ElasticSearch集群的安装
1. 下载
官网地址:https://www.elastic.co/downloads/elasticsearch
点击downloads

关于ES的版本,现在大多数网上和书写的都是ES 2.x系列的书,有部分比较新的讲的是ES 5的
没有3,4一说。是这样的,ELK 产品是一个非常完善的系统,跟大数据没什么关系,后来我们发现可以处理一些大数据的东西。可以和hadoop和spark整合。因为ELK三个产品是不同的公司出的。有一天一个人想把它们整合在一起,发现E发展到了2的版本,L发展到了3的版本,K发展到了4的版本。这样会有一个问题,什么样的hive和hbase配合什么样的hadoop,这样引发了一个匹配不匹配的问题。三个厂家就决定,从下一代产品我们一起升级就从5版本开始,所以如果你E用5.6,L也应该用5.6,K也应该用5.6,这样就进行了匹配。
这里我们下载安装目前最新版本的6.3.2的ES,注意需要安装好JDK,因为是由java开发的。
2. 安装并启动ES
直接解压即可,进入bin目录,本文为 G:\myProgram\ElasticSearch\elasticsearch-6.3.2\bin 下进入cmd
输入elasticsearch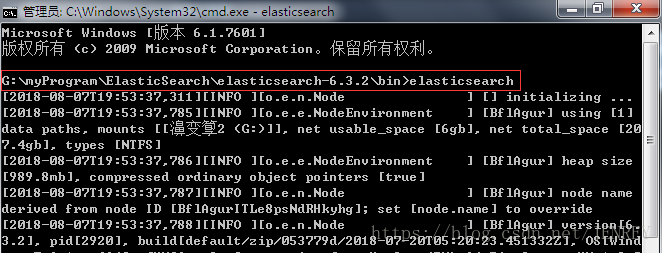
验证ES是否启动成功
在浏览器中输入 http://localhost:9200看到如下所示图片即为成功
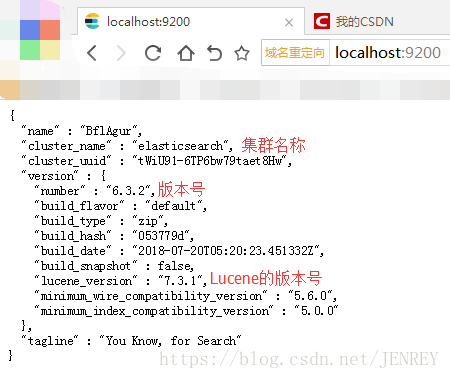
3. ES的分布式原理
Elasticsearch 也是会对数据进行切分,同时每一个分片会保存多个副本,其原因和 HDFS 是一样的,都是为了保证分布式环境下的高可用。
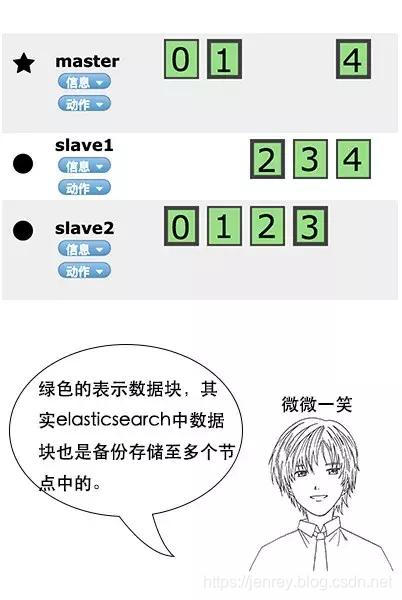
在 Elasticsearch 中,是master-slave架构。节点是对等的,节点间会通过自己的一些规则选取集群的 Master,Master 会负责集群状态信息的改变,并同步给其他节点。
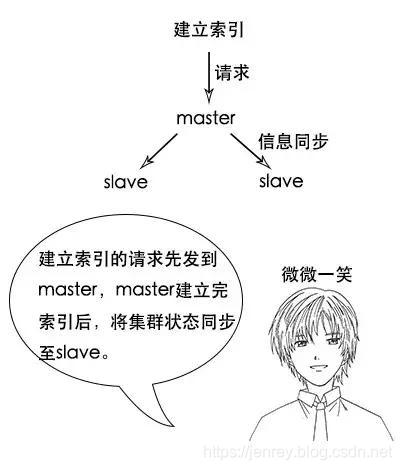
这样写入性能会不会很低???注意,只有建立索引和类型需要经过 Master,数据的写入有一个简单的 Routing 规则,可以 Route 到集群中的任意节点,所以数据写入压力是分散在整个集群的。