5. Dubbo扩展机制 - 加载扩展点
1. 开篇
本文主要讲解,Dubbo是如何解析META-INF文件夹下接口文件的。
2. 源码分析
2.1 加载扩展点类
解析文件的方法入口是在这里:org.apache.dubbo.common.extension.ExtensionLoader#loadExtensionClasses。
private Map<String, Class<?>> loadExtensionClasses() {
// 缓存默认扩展点
cacheDefaultExtensionName();
Map<String, Class<?>> extensionClasses = new HashMap<>();
for (LoadingStrategy strategy : strategies) {
// 加载文件夹中接口类的内容
loadDirectory(extensionClasses, strategy.directory(), type.getName(), strategy.preferExtensionClassLoader(),
strategy.overridden(), strategy.excludedPackages());
loadDirectory(extensionClasses, strategy.directory(), type.getName().replace("org.apache", "com.alibaba"),
strategy.preferExtensionClassLoader(), strategy.overridden(), strategy.excludedPackages());
}
return extensionClasses;
}这段代码主要干了两件事:
- 缓存默认扩展点,也就是
@SPI的值作为默认扩展点。 - 根据某种策略来读取对应的文件夹。
- 读取文件里的文件找到类,访问
map中,并且返回。
2.2 默认扩展点
缓存默认扩展点
private void cacheDefaultExtensionName() {
// @SPI("xxx")
final SPI defaultAnnotation = type.getAnnotation(SPI.class);
if (defaultAnnotation == null) {
return;
}
String value = defaultAnnotation.value();
if ((value = value.trim()).length() > 0) {
String[] names = NAME_SEPARATOR.split(value);
if (names.length > 1) {
throw new IllegalStateException("More than 1 default extension name on extension " + type.getName()
+ ": " + Arrays.toString(names));
}
if (names.length == 1) {
cachedDefaultName = names[0];
}
}
}先判断接口上有没有@SPI注解,如果没有的话也就没有默认的扩展点。
如果有@SPI注解,并且有对应的value值,则把value值作为默认扩展点的名字。
2.3 读取策略
从上面代码我们可以看到,有个for循环,遍历某种策略,来读取文件内容,我们来看下这种策略。
private static volatile LoadingStrategy[] strategies = loadLoadingStrategies();
private static LoadingStrategy[] loadLoadingStrategies() {
return StreamSupport.stream(ServiceLoader.load(LoadingStrategy.class)
.spliterator(), false)
.sorted()
.toArray(LoadingStrategy[]::new);
}从这段代码中,可以看到一个熟悉的类ServiceLoader,这个不就是JAVA SPI的类吗?那肯定在某个META-INF/services/目录下有个文件叫org.apache.dubbo.common.extension.LoadingStrategy的文件。根据dubbo的命名规则,应该在common工程里。
org.apache.dubbo.common.extension.DubboInternalLoadingStrategy
org.apache.dubbo.common.extension.DubboLoadingStrategy
org.apache.dubbo.common.extension.ServicesLoadingStrategy也就是这3种策略来读取文件。打开3个类的内容,这3个类分别对应3个文件夹,内容比较简单。
DubboInternalLoadingStrategy类对应META-INF/dubbo/internal/。
DubboLoadingStrategy类对应META-INF/dubbo/。
ServicesLoadingStrategy类对应META-INF/services/。
2.4 loadDirectory
读取目录文件内容,我们看到调了两次loadDirectory,其中第二个把org.apache替换为com.alibaba,这个是为了做兼容,因为dubbo原来是alibaba开发的,后来捐献给apache。
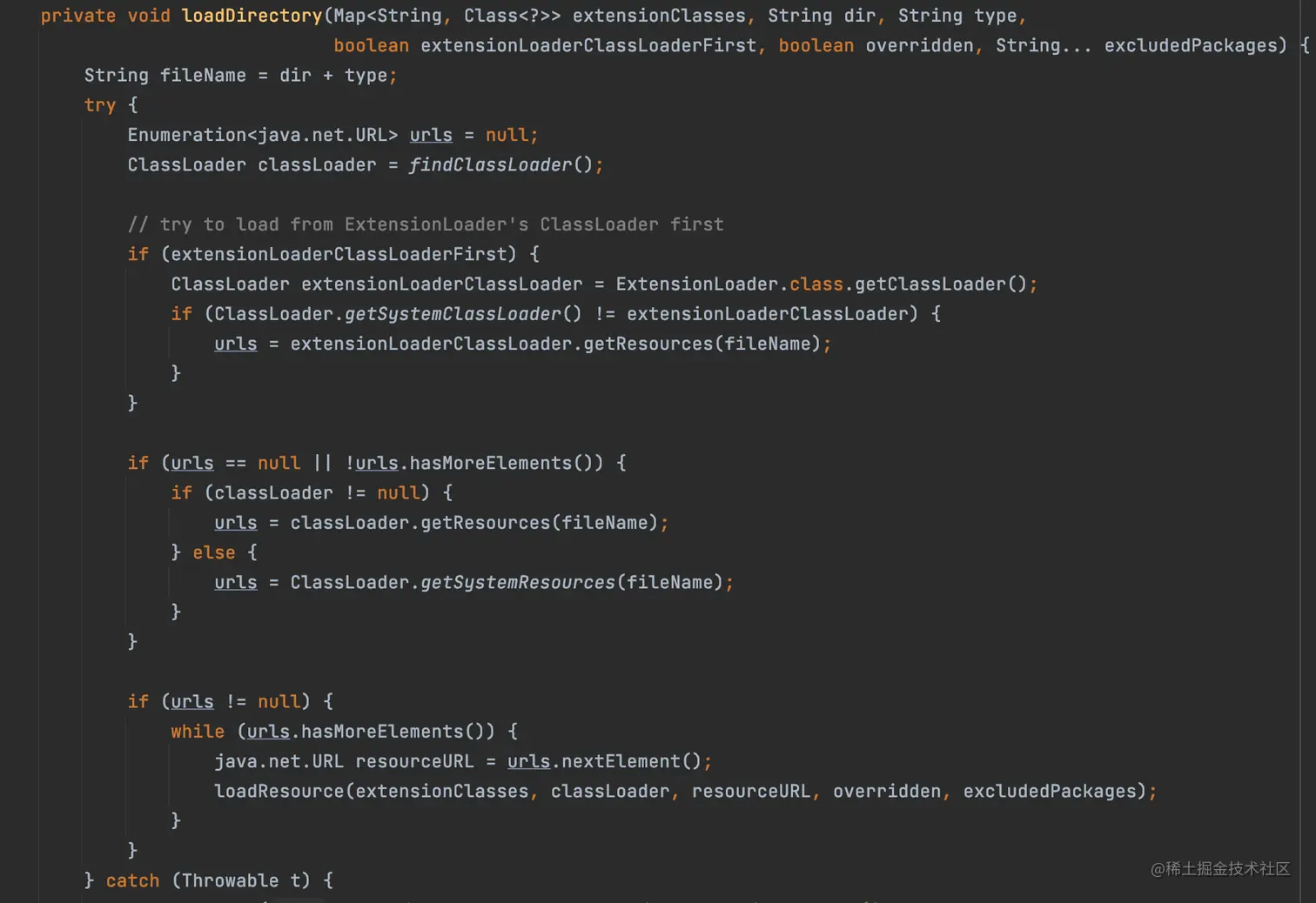
从代码中看到,先把上面3个文件夹拼接上接口类的名字作为文件名,然后通过类加载器来找到文件,再通过loadResource方法解析文件。
值的一说的是,类加载器是用的哪个类加载器呢?
private static ClassLoader findClassLoader() {
return ClassUtils.getClassLoader(ExtensionLoader.class);
}
public static ClassLoader getClassLoader(Class<?> clazz) {
ClassLoader cl = null;
try {
cl = Thread.currentThread().getContextClassLoader();
} catch (Throwable ex) {
}
if (cl == null) {
cl = clazz.getClassLoader();
if (cl == null) {
try {
cl = ClassLoader.getSystemClassLoader();
} catch (Throwable ex) {
}
}
}
return cl;
}首页查看当前线程的类加载器,如果没有的话,就找ExtensionLoader这个类是由哪个类加载器进行加载的,如果还没有的话,就返回系统类加载器。
那ExtensionLoader是由哪个类加载器加载的呢?如果我们直接运行dubbo源码,那肯定是App类加载器了。如果我们是在项目中引入dubbo的jar包,那就不一样了。如果是springboot打成的fatjar,那就是springboot自定义的类加载器了。
2.5 loadResource
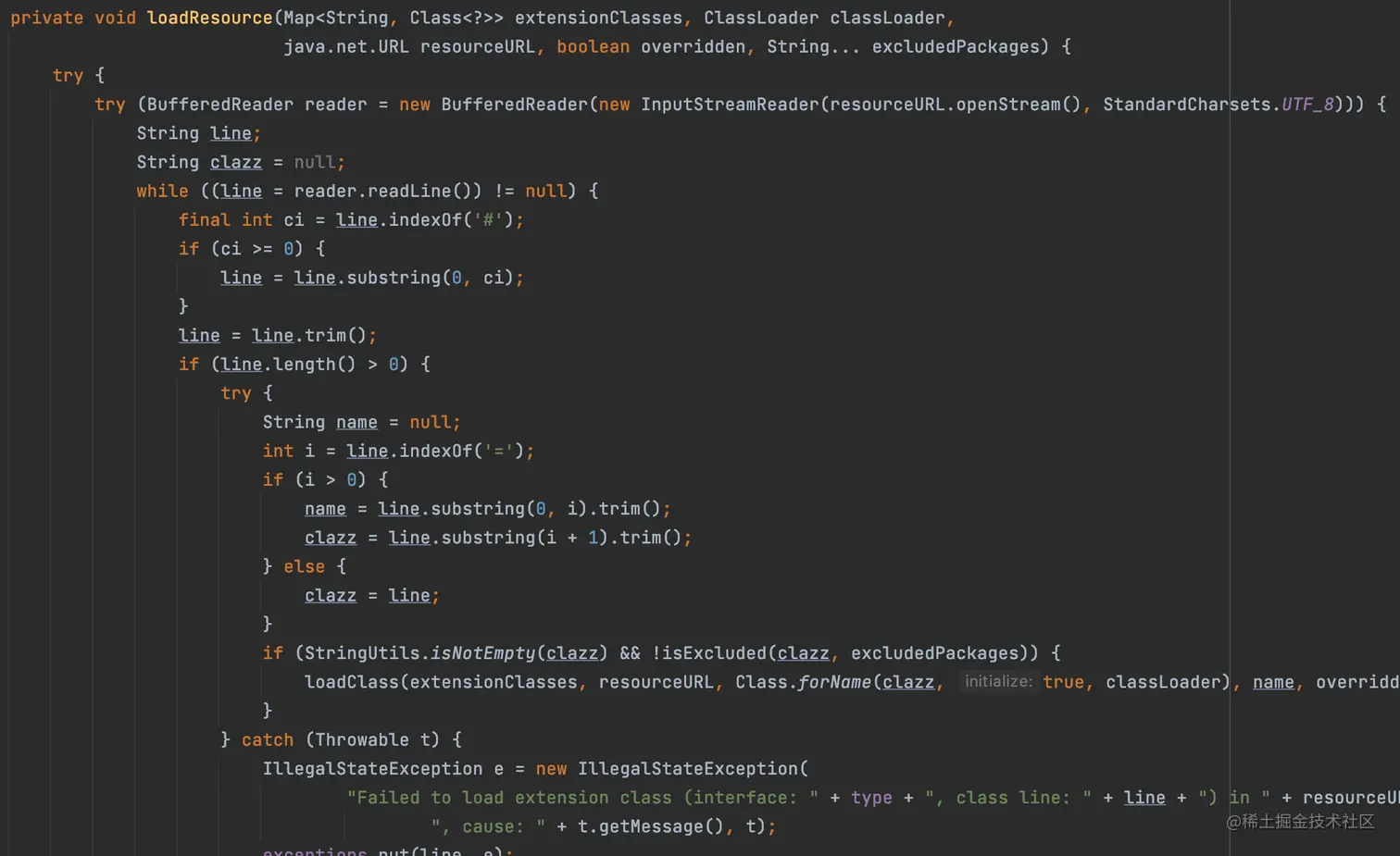
读取文件内容,这段代码也挺简单,逐行读取内容,如果有#号取#号前面的内容。然后把每一行按=号分隔,前面是name,后面是类名。然后,把name作为key,把类名加载成类作为value,放入extensionClasses这个map中。
2.6 loadClass
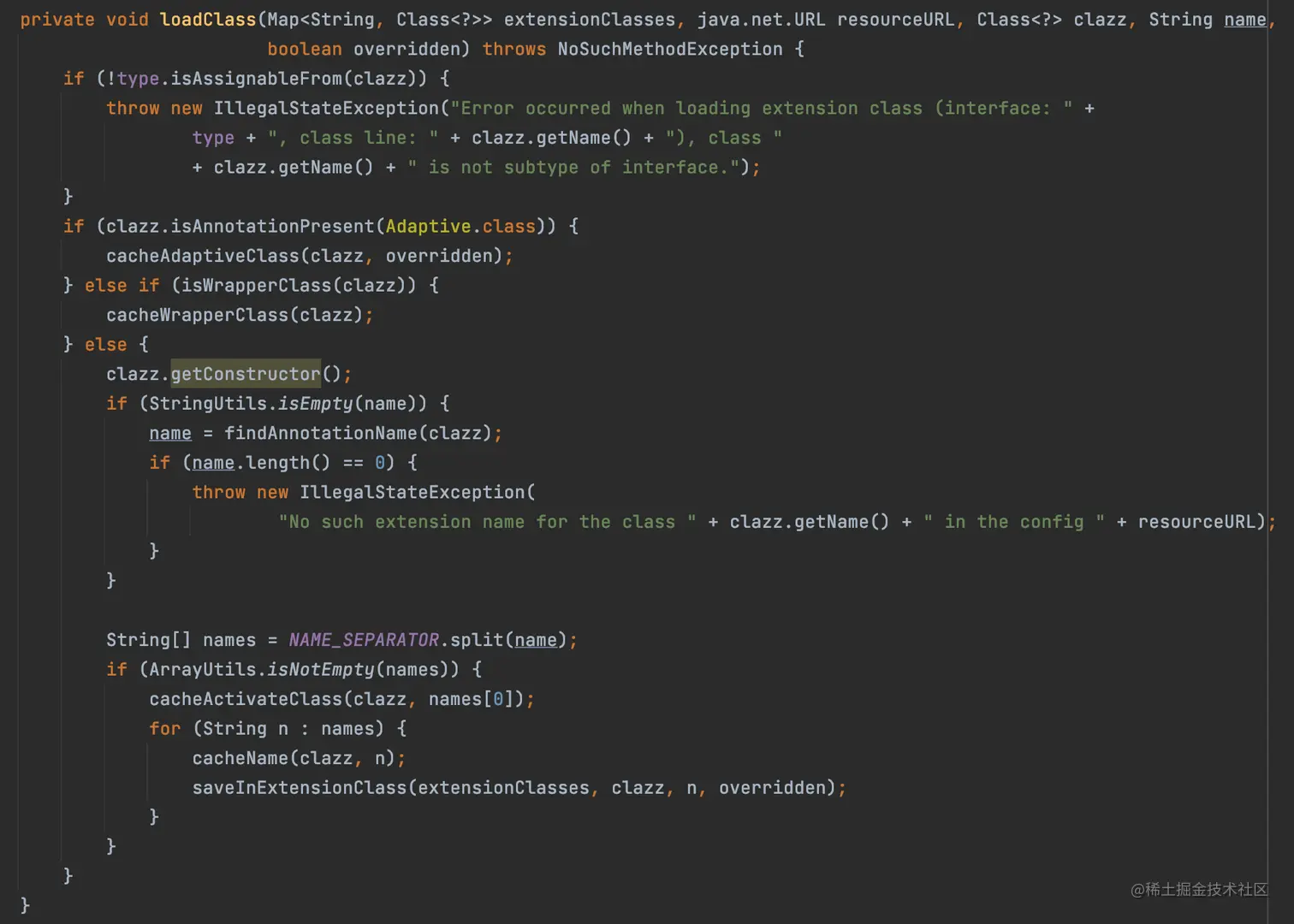
首先判断传进来的类,是否实现了type这个接口,如果没有实现则抛出异常。再看这个类是否存在Adaptive注解,如果存在,则缓存一下。 判断这个类是否是一个Wrapper类,判断逻辑就是查看这个类是否存在一个含有type接口的构造函数。 我们看到一个获取构造方法的代码clazz.getConstructor()并没有变量接收这是为啥?
这是因为这些扩展点类,需要一个无参的构造函数,如果没有的话,会直接报错。
如果这个类没有对应的name,则查看这个类有没有Extension注解,有的话取这个注解的值作为name,如果没有则用小写的类名。
例如下面这个示例,不过这种方式已经不推荐使用了。
@Extension("yoyo")
public class YoYo implements Mascot {
@Override
public String getName() {
return "YoYo";
}
}继续,saveInExtensionClass方法的作用是,把name和对应的类放入extensionClassesmap中。
cacheActivateClass方法是判断创建的类有没有Activate注解,如果有的话,则放到cachedActivates缓存中。
关于Activate注解后面再详细的介绍。
3. 后记
本篇文章,主要介绍了Dubbo是如何解析META-INF文件夹下接口对应文件的,对解析过程做了简单的源码介绍。