14. 图
定义
图是一种非线性的数据结构,表示多对多的关系。图(Graph)是由顶点的有穷非空集合和顶点之间边的集合组成,通常表示为:G(V, E),其中,G表示一个图,V是图G中顶点的集合,E是图G中边的集合。拿微信举例子吧。我们可以把每个用户看作一个顶点。如果两个用户之间互加好友,那就在两者之间建立一条边。所以,整个微信的好友关系就可以用一张图来表示。其中,每个用户有多少个好友,对应到图中,就叫做顶点的度(degree),就是跟顶点相连接的边的条数。如果用户 A 关注了用户 B,我们就在图中画一条从 A 到 B 的带箭头的边,来表示边的方向。如果用户 A 和用户 B 互相关注了,那我们就画一条从 A 指向 B 的边,再画一条从 B 指向 A 的边。我们把这种边有方向的图叫做有向图。以此类推,我们把边没有方向的图就叫做无向图。 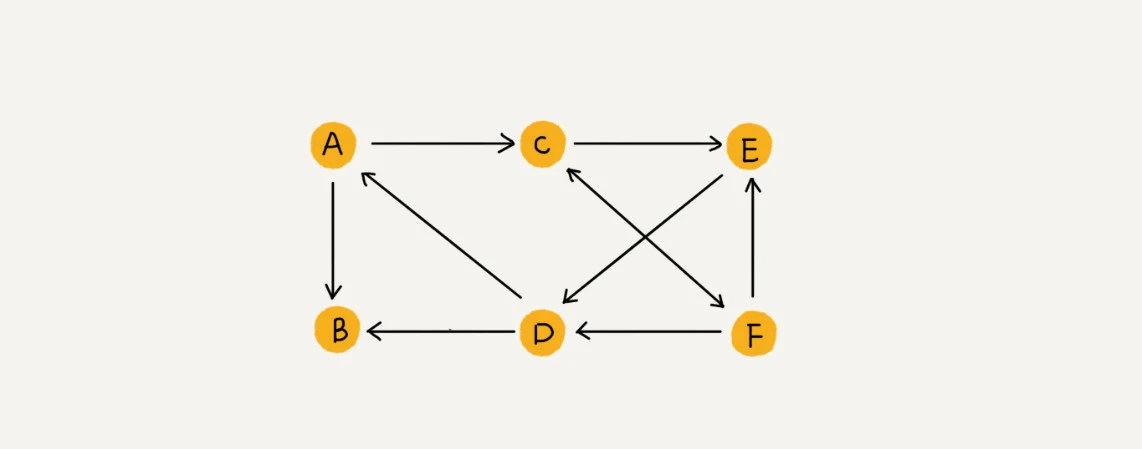 QQ 中的社交关系要更复杂一点。不知道你有没有留意过 QQ 亲密度这样一个功能。QQ 不仅记录了用户之间的好友关系,还记录了两个用户之间的亲密度,如果两个用户经常往来,那亲密度就比较高;如果不经常往来,亲密度就比较低,这种场景可以在边上记录两个用户的亲密度权重,这种边上有权重的图叫做带权图。
QQ 中的社交关系要更复杂一点。不知道你有没有留意过 QQ 亲密度这样一个功能。QQ 不仅记录了用户之间的好友关系,还记录了两个用户之间的亲密度,如果两个用户经常往来,那亲密度就比较高;如果不经常往来,亲密度就比较低,这种场景可以在边上记录两个用户的亲密度权重,这种边上有权重的图叫做带权图。 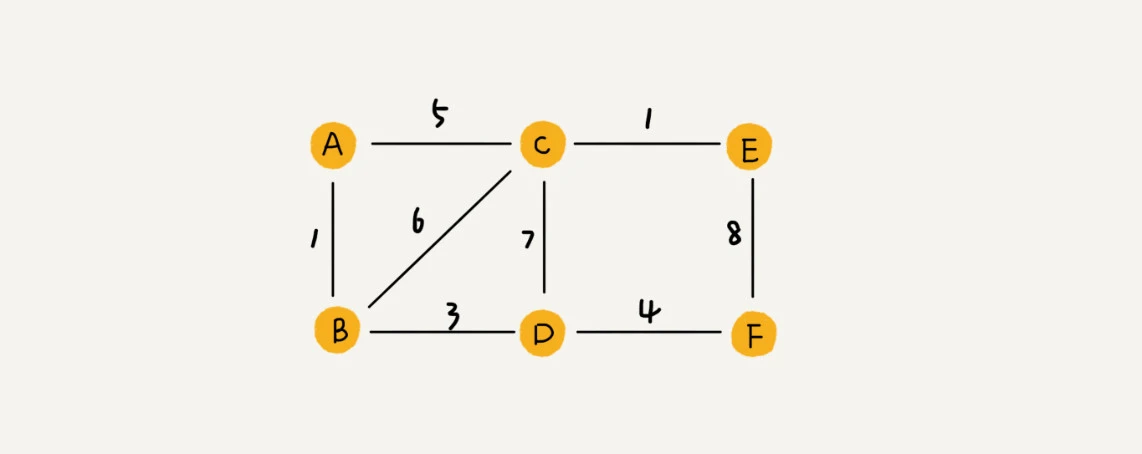 在图中需要注意的是:
在图中需要注意的是:
- 线性表和树可以看做特殊的图。
- 线性表中我们把数据元素叫元素,树中将数据元素叫结点,在图中数据元素,我们则称之为顶点(Vertex)
- 线性表可以没有元素,称为空表;树中可以没有节点,称为空树;但是,在图中不允许没有顶点(有穷非空性)
- 线性表中的各元素是线性关系,树中的各元素是层次关系,而图中各顶点的关系是用边来表示(边集可以为空)。
如何存储图
邻接矩阵存储法
邻接矩阵的底层依赖一个二维数组。对于无向图来说,如果顶点 i 与顶点 j 之间有边,我们就将 A[i][j]和 A[j][i]标记为 1;对于有向图来说,如果顶点 i 到顶点 j 之间,有一条箭头从顶点 i 指向顶点 j 的边,那我们就将 A[i][j]标记为 1。同理,如果有一条箭头从顶点 j 指向顶点 i 的边,我们就将 A[j][i]标记为 1。对于带权图,数组中就存储相应的权重。 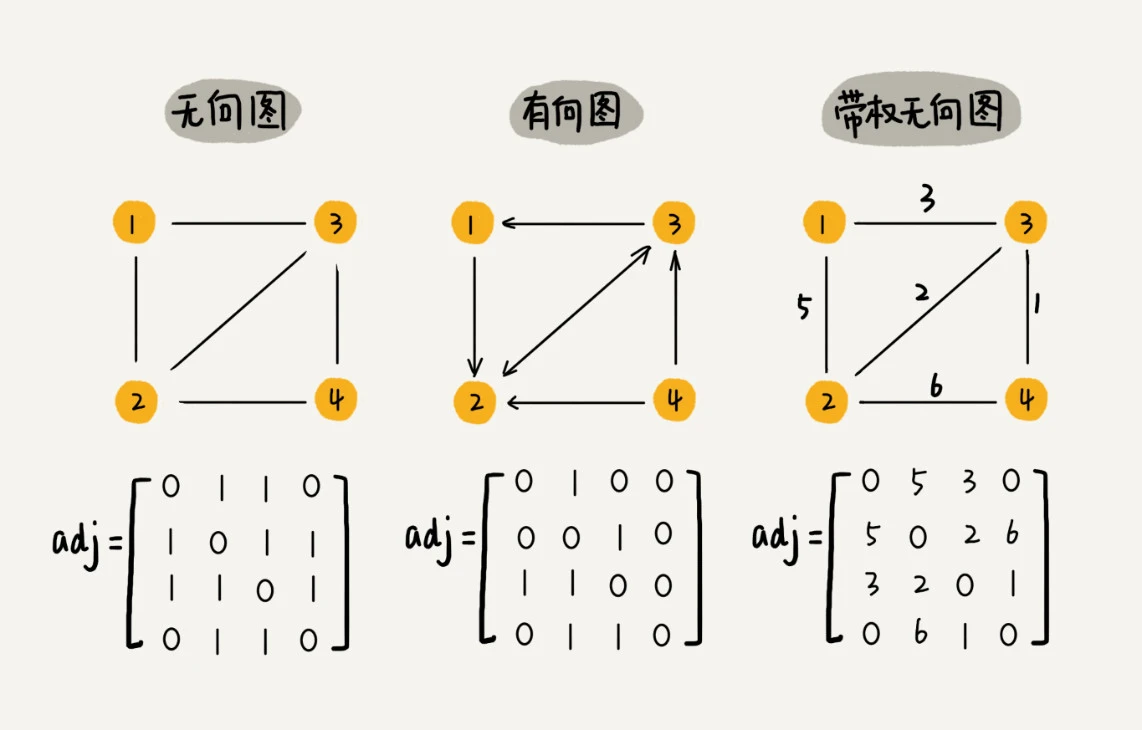 用邻接矩阵来表示一个图,虽然简单、直观,但是比较浪费存储空间。为什么这么说呢?对于无向图来说,如果 A[i][j]等于 1,那 A[j][i]也肯定等于 1。实际上,我们只需要存储一个就可以了。也就是说,无向图的二维数组中,如果我们将其用对角线划分为上下两部分,那我们只需要利用上面或者下面这样一半的空间就足够了,另外一半白白浪费掉了。还有,如果我们存储的是稀疏图(Sparse Matrix),也就是说,顶点很多,但每个顶点的边并不多,那邻接矩阵的存储方法就更加浪费空间了。比如微信有好几亿的用户,对应到图上就是好几亿的顶点。但是每个用户的好友并不会很多,一般也就三五百个而已。如果我们用邻接矩阵来存储,那绝大部分的存储空间都被浪费了。
用邻接矩阵来表示一个图,虽然简单、直观,但是比较浪费存储空间。为什么这么说呢?对于无向图来说,如果 A[i][j]等于 1,那 A[j][i]也肯定等于 1。实际上,我们只需要存储一个就可以了。也就是说,无向图的二维数组中,如果我们将其用对角线划分为上下两部分,那我们只需要利用上面或者下面这样一半的空间就足够了,另外一半白白浪费掉了。还有,如果我们存储的是稀疏图(Sparse Matrix),也就是说,顶点很多,但每个顶点的边并不多,那邻接矩阵的存储方法就更加浪费空间了。比如微信有好几亿的用户,对应到图上就是好几亿的顶点。但是每个用户的好友并不会很多,一般也就三五百个而已。如果我们用邻接矩阵来存储,那绝大部分的存储空间都被浪费了。
邻接表存储法
针对上面邻接矩阵比较浪费内存空间的问题,我们来看另外一种图的存储方法,邻接表。邻接表点像散列表,每个顶点对应一条链表,链表中存储的是与这个顶点相连接的其他顶点。 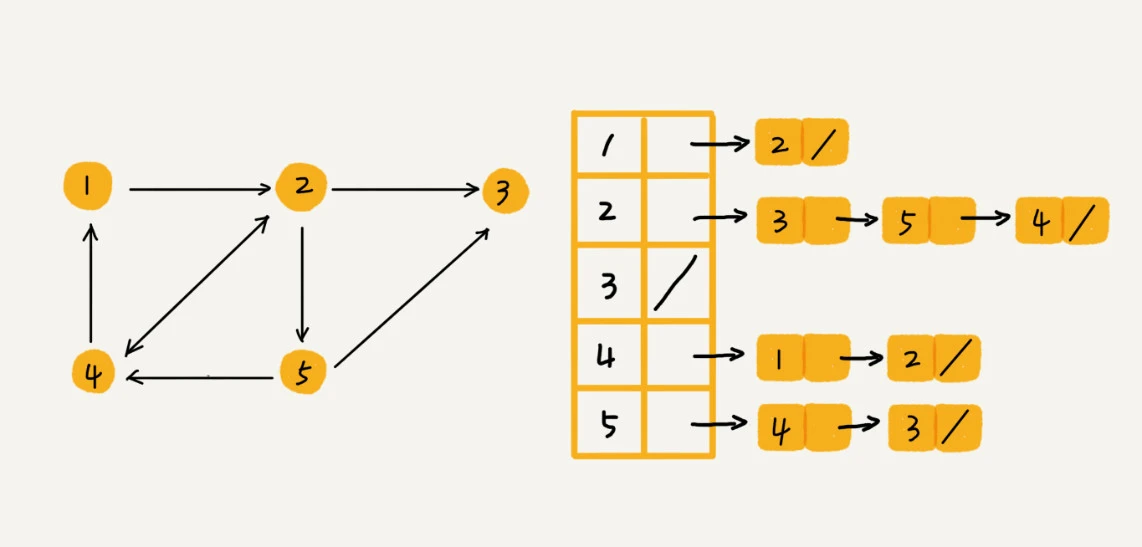 邻接矩阵存储方法的缺点是比较浪费空间,但是优点是查询效率高,而且方便矩阵运算。邻接表存储方法中每个顶点都对应一个链表,存储与其相连接的其他顶点。尽管邻接表的存储方式比较节省存储空间,但链表不方便查找,所以查询效率没有邻接矩阵存储方式高。针对这个问题,邻接表还有改进升级版,即将链表换成更加高效的动态数据结构,比如平衡二叉查找树、跳表、散列表等。简单的代码实现:
邻接矩阵存储方法的缺点是比较浪费空间,但是优点是查询效率高,而且方便矩阵运算。邻接表存储方法中每个顶点都对应一个链表,存储与其相连接的其他顶点。尽管邻接表的存储方式比较节省存储空间,但链表不方便查找,所以查询效率没有邻接矩阵存储方式高。针对这个问题,邻接表还有改进升级版,即将链表换成更加高效的动态数据结构,比如平衡二叉查找树、跳表、散列表等。简单的代码实现:
public class Graph
{
public int _count;
private LinkList<int>[] _array;
public Graph(int count)
{
_count = count;
_array = new LinkList<int>[_count];
}
public void AddEdge(int node1, int node2)
{
if (_array[node1] == null)
{
_array[node1] = new LinkList<int>();
}
if (_array[node2] == null)
{
_array[node2] = new LinkList<int>();
}
_array[node1].Insert(node2);
_array[node2].Insert(node1);
}
}