系统变量和用户变量
变量
在MySQL数据库的存储过程和函数中,可以使用变量来存储查询或计算的中间结果数据,或者输出最终的结果数据。
在MySQL数据库中,变量分为系统变量以及用户自定义变量 。
1.系统变量
1.1 系统变量分类
变量由系统定义,不是用户定义,属于 服务器 层面。启动MySQL服务,生成MySQL服务实例期间,MySQL将为MySQL服务器内存中的系统变量赋值,这些系统变量定义了当前MySQL服务实例的属性、特征。这些系统变量的值要么是 编译MySQL时参数 的默认值,要么是 配置文件 (例如my.ini等)中的参数值。
系统变量分为全局系统变量(需要添加 global 关键字)以及会话系统变量(需要添加 session 关键字),有时也把全局系统变量简称为全局变量,有时也把会话系统变量称为local变量。如果不写,默认会话级别。静态变量(在 MySQL 服务实例运行期间它们的值不能使用 set 动态修改)属于特殊的全局系统变量。
每一个MySQL客户机成功连接MySQL服务器后,都会产生与之对应的会话。会话期间,MySQL服务实例会在MySQL服务器内存中生成与该会话对应的会话系统变量,这些会话系统变量的初始值是全局系统变量值的复制。如下图:
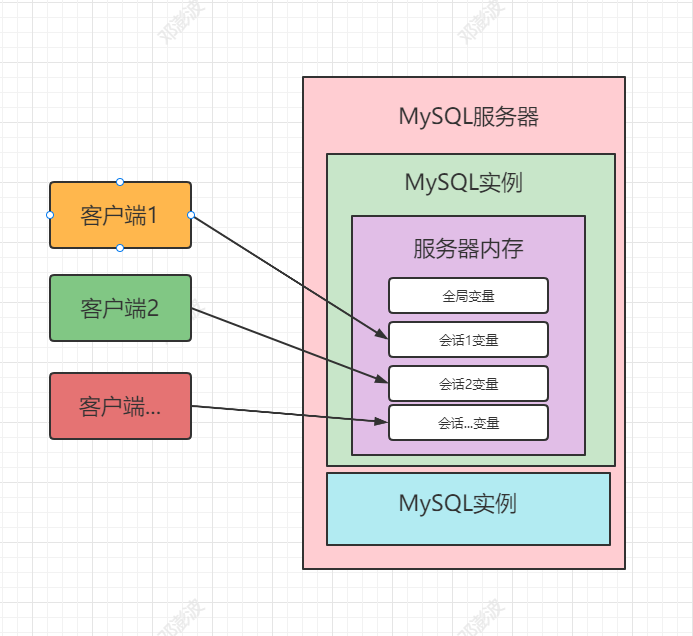
全局系统变量的特点:针对所有会话都有效,但是不能跨重启。
会话系统变量的特点:
- 针对当前会话有效,当前会话对某个会话系统变量值的修改,不会影响其他会话同一个会话系统变量的值。
- 会话1对某个全局系统变量值的修改会导致会话2中同一个全局系统变量值的修改。
在MySQL中有些系统变量只能是全局的,例如 max_connections 用于限制服务器的最大连接数;有些系统变量作用域既可以是全局又可以是会话,例如 character_set_client 用于设置客户端的字符集;有些系统变量的作用域只能是当前会话,例如 pseudo_thread_id 用于标记当前会话的 MySQL 连接 ID。
1.2 查看系统变量
1.2.1 查看所有或部分系统变量
# 查看所有变量
SHOW GLOBAL VARIABLES;
#查看所有会话变量
SHOW SESSION VARIABLES;
#或
SHOW VARIABLES;#查看满足条件的部分系统变量。
SHOW GLOBAL VARIABLES LIKE '%标识符%';
#查看满足条件的部分会话变量
SHOW SESSION VARIABLES LIKE '%标识符%';举例:
SHOW GLOBAL VARIABLES LIKE 'admin_%';1.2.2 查看指定系统变量
作为 MySQL 编码规范,MySQL 中的系统变量以 两个“@” 开头,其中“@@global”仅用于标记全局系统变量,“@@session”仅用于标记会话系统变量。“@@”首先标记会话系统变量,如果会话系统变量不存在,则标记全局系统变量。
#查看指定的系统变量的值
SELECT @@global.变量名;
#查看指定的会话变量的值
SELECT @@session.变量名;
#或者
SELECT @@变量名;举例:
# 查看系统全局变量
SELECT @@global.autocommit;
# 查看会话变量
SELECT @@session.character_set_client;1.2.3 修改系统变量的值
有些时候,数据库管理员需要修改系统变量的默认值,以便修改当前会话或者MySQL服务实例的属性、特征。具体方法:
方式1:修改MySQL 配置文件 ,继而修改MySQL系统变量的值(该方法需要重启MySQL服务)
方式2:在MySQL服务运行期间,使用“set”命令重新设置系统变量的值
#为某个系统变量赋值
#方式1:
SET @@global.变量名=变量值;
#方式2:
SET GLOBAL 变量名=变量值;
#为某个会话变量赋值
#方式1:
SET @@session.变量名=变量值;
#方式2:
SET SESSION 变量名=变量值;举例说明:
SELECT @@global.autocommit;
SET GLOBAL autocommit=0;SELECT @@session.tx_isolation;
SET @@session.tx_isolation='read-uncommitted';SET GLOBAL max_connections = 1000;
SELECT @@global.max_connections;2.用户变量
2.1 用户变量分类
用户变量是用户自己定义的,作为 MySQL 编码规范,MySQL 中的用户变量以 一个“@” 开头。根据作用范围不同,又分为会话用户变量和局部变量 。
会话用户变量:作用域和会话变量一样,只对
当前连接会话有效。局部变量:只在 BEGIN 和 END 语句块中有效。局部变量只能在
存储过程和函数中使用。
2.2 会话用户变量
变量的定义:
#方式1:“=”或“:=”
SET @用户变量 = 值;
SET @用户变量 := 值;
#方式2:“:=” 或 INTO关键字
SELECT @用户变量 := 表达式 [FROM 等子句];
SELECT 表达式 INTO @用户变量 [FROM 等子句];查看用户变量的值 (查看、比较、运算等)
SELECT @用户变量举例说明
SET @a = 100;
SELECT @a;SELECT @num := COUNT(*) FROM student;
SELECT @num;SELECT AVG(grade) INTO @avggrade FROM score;
SELECT @avggrade;SELECT @bobo; #查看某个未声明的变量时,将得到NULL值2.3 局部变量
定义:可以使用 DECLARE 语句定义一个局部变量
作用域:仅仅在定义它的 BEGIN ... END 中有效
位置:只能放在 BEGIN ... END 中,而且只能放在第一句
BEGIN
#声明局部变量
DECLARE 变量名1 变量数据类型 [DEFAULT 变量默认值];
DECLARE 变量名2,变量名3,... 变量数据类型 [DEFAULT 变量默认值];
#为局部变量赋值
SET 变量名1 = 值;
SELECT 值 INTO 变量名2 [FROM 子句];
#查看局部变量的值
SELECT 变量1,变量2,变量3;
END定义变量
DECLARE 变量名 类型 [default 值]; # 如果没有DEFAULT子句,初始值为NULL案例:
DECLARE myparam INT DEFAULT 100;变量赋值
方式1:一般用于赋简单的值
SET 变量名=值;
SET 变量名:=值;方式2:一般用于赋表中的字段值
SELECT 字段名或表达式 INTO 变量名 FROM 表;使用变量
SELECT 局部变量名;案例讲解:
案例1:声明局部变量,并分别赋值为student表中id为902的name和department
DELIMITER //
CREATE PROCEDURE set_value()
BEGIN
DECLARE stu_name VARCHAR(25);
DECLARE stu_department VARCHAR(30);
SELECT name ,department into stu_name,stu_department
FROM student
where id = 902 ;
END //
DELIMITER ;案例2:声明两个变量,求和并打印 (分别使用会话用户变量、局部变量的方式实现)
#方式1:使用用户变量
SET @m=1;
SET @n=1;
SET @sum=@m+@n;
SELECT @sum;#方式2:使用局部变量
DELIMITER //
CREATE PROCEDURE add_value()
BEGIN
#局部变量
DECLARE m INT DEFAULT 1;
DECLARE n INT DEFAULT 3;
DECLARE SUM INT;
SET SUM = m+n;
SELECT SUM;
END //
DELIMITER ;案例3:创建存储过程“different_grade”查询两个学员的成绩总差,并用IN参数id1,id2接收学员编号,用OUT参数dif_grade输出总成绩差的结果。
DELIMITER //
CREATE PROCEDURE different_grade(IN id1 int ,IN id2 int ,OUT dif_grade int)
BEGIN
# 声明具备变量
DECLARE grade1 INT;
DECLARE grade2 INT;
SELECT sum(grade) into grade1 from score where stu_id = id1;
SELECT sum(grade) into grade2 from score where stu_id = id2;
SET dif_grade = abs(grade1 - grade2 );
END //
DELIMITER ;调用
CALL different_grade(902,903,@dif_grade) ;查看
select @dif_grade;2.4 两则对比
| 作用域 | 定义位置 | 语法 | |
|---|---|---|---|
| 会话变量 | 当前会话 | 会话的任何地方 | 加@符号,不用指定类型 |
| 局部变量 | 定义它的BEGIN END中 | BEGIN END的第一句话 | 一般不用加@,需要指定类型 |
在Java中针对异常的处理方式?
定义异常-->系统提供的异常还要我们自定义的异常
处理或者抛出异常
3.定义条件和处理程序
3.1 问题场景
先来看个场景:

执行一条插入语句,因为id是主键,没有设置自增,所以在插入的时候我们必须要添加该字段的值,但是上面没有添加就出现了1364的错误提示信息,针对这种情况我们应该怎么处理呢?或者看下面这个存储过程。
# 创建存储过程
CREATE PROCEDURE insertStudentData()
BEGIN
SET @x = 1;
insert into student(name)values('TOM');
SET @x = 2;
insert into student(name)values('James');
SET @x = 3;
END ;
# 调用存储过程
call insertStudentData() ;
# 查看变量
select @x ;输出的结果为:
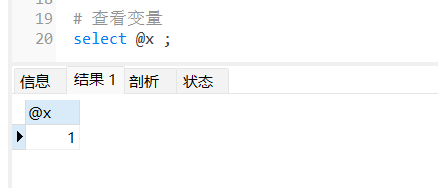
可以看到存储过程调用中也出现了问题,程序没有执行完成,针对这种问题我们就需要通过定义条件和处理程序来解决了。
定义条件是事先定义程序执行过程中可能遇到的问题
处理程序定义了在遇到问题时应当采取的处理方式,并且保证存储过程或函数在遇到警告或错误时能继续执行。这样可以增强存储程序处理问题的能力,避免程序异常停止运行。类似于Java中的异常处理。
说明:定义条件和处理程序在存储过程、存储函数中都是支持的
3.2 定义条件
定义条件就是给MySQL中的错误码命名,这有助于存储的程序代码更清晰。它将一个 错误名字 和 指定的 错误条件 关联起来。这个名字可以随后被用在定义处理程序的 DECLARE HANDLER 语句中。
定义条件使用DECLARE语句,语法格式如下:
DECLARE 错误名称 CONDITION FOR 错误码(或错误条件)错误码的说明:
MySQL_error_code 和 sqlstate_value 都可以表示MySQL的错误。
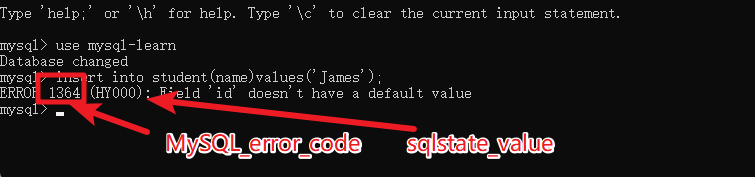
上图中的 1364是 MySQL_error_code, HY000 是sqlstate_value
| 错误码 | 说明 |
|---|---|
| MySQL_error_code | 是数值类型错误代码,比如 1364 |
| sqlstate_value | 是长度为5的字符串类型错误代码,比如 HY000 |
案例:定义“Field_Not_Be_NULL”错误名与MySQL中违反非空约束的错误类型是“ERROR 1364 (HY000)”对应。
#使用MySQL_error_code
DECLARE Field_Not_Be_NULL CONDITION FOR 1364;
#使用sqlstate_value
DECLARE Field_Not_Be_NULL CONDITION FOR SQLSTATE 'HY000';3.3 定义处理程序
可以为SQL执行过程中发生的某种类型的错误定义特殊的处理程序。定义处理程序时,使用DECLARE语句的语法如下:
DECLARE 处理方式 HANDLER FOR 错误类型 处理语句语法说明
| 组成内容 | 说明 |
|---|---|
| 处理方式 | 处理方式有3个取值:CONTINUE、EXIT、UNDO CONTINUE :表示遇到错误不处理,继续执行。 EXIT :表示遇到错误马上退出。 UNDO :表示遇到错误后撤回之前的操作。MySQL中暂时不支持这样的操作。 |
| 错误类型 | 也就是条件: SQLSTATE '字符串错误码' :表示长度为5的sqlstate_value类型的错误代码; MySQL_error_code :匹配数值类型错误代码; 错误名称 :表示DECLARE ... CONDITION定义的错误条件名称。 SQLWARNING :匹配所有以01开头的SQLSTATE错误代码; NOT FOUND :匹配所有以02开头的SQLSTATE错误代码; SQLEXCEPTION :匹配所有没有被SQLWARNING或NOT FOUND捕获的SQLSTATE错误代码; |
| 处理语句 | 如果出现上述条件之一,则采用对应的处理方式,并执行指定的处理语句。 语句可以是像“ SET 变量 = 值 ”这样的简单语句,也可以是使用 BEGIN ... END 编写的复合语句。 |
定义处理程序的几种方式,代码如下:
#方法1:捕获sqlstate_value
DECLARE CONTINUE HANDLER FOR SQLSTATE '42S02' SET @info = 'NO_SUCH_TABLE';
#方法2:捕获mysql_error_value
DECLARE CONTINUE HANDLER FOR 1146 SET @info = 'NO_SUCH_TABLE';
#方法3:先定义条件,再调用
DECLARE no_such_table CONDITION FOR 1146;
DECLARE CONTINUE HANDLER FOR NO_SUCH_TABLE SET @info = 'NO_SUCH_TABLE';
#方法4:使用SQLWARNING
DECLARE EXIT HANDLER FOR SQLWARNING SET @info = 'ERROR';
#方法5:使用NOT FOUND
DECLARE EXIT HANDLER FOR NOT FOUND SET @info = 'NO_SUCH_TABLE';
#方法6:使用SQLEXCEPTION
DECLARE EXIT HANDLER FOR SQLEXCEPTION SET @info = 'ERROR';3.4 案例解决
通过上面的介绍我们可以来解决前面出现的问题了,先删除之前的存储过程
DROP PROCEDURE insertStudentData然后开始重新创建存储过程,并添加对应的处理程序
CREATE PROCEDURE insertStudentData()
BEGIN
#处理的方法一:
DECLARE CONTINUE HANDLER FOR 1364 SET @proc_value=-1;
#处理的方法二:
#DECLARE CONTINUE HANDLER FOR SQLSTATE 'HY000' SET @proc_value=-1;
#处理的方法三
# 先定义条件
# DECLARE field_not_null CONDITION FOR SQLSTATE 'HY000'
# DECLARE CONTINUE HANDLER FOR field_not_null SET @proc_value=-1;
SET @x = 1;
insert into student(name)values('TOM');
SET @x = 2;
insert into student(name)values('James');
SET @x = 3;
END ;调用存储过程
CALL insertStudentData() ;查询变量
SELECT @x , @proc_value;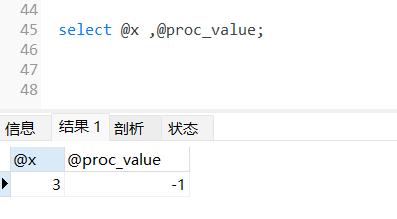
通过处理程序的操作,我们可以发现存储过程在执行中虽然有问题,但是是执行完成了,出现的错误被处理程序捕获到了,并更新了相关的变量,那么我们就可以在过程处理完成后基于变量的信息做出相应的操作了,从而实现了对存储过程执行中出现问题的处理。