4. 理论| 一致性算法详解(CAP、BASE、2PC、3PC)
1. CAP 定理
1.1 简介
CAP 定理指的是在一个分布式系统中, Consistency(一致性)、 Availability(可用性)、Partition tolerance(分区容错性),三者不可兼得。
一致性(C):分布式系统中多个主机之间是否能够保持数据一致的特性。即,当系统数据发生更新操作后,各个主机中的数据仍然处于一致的状态。可用性(A):系统提供的服务必须一直处于可用的状态,即对于用户的每一个请求,系统总是可以在有限的时间内对用户做出响应。分区容错性(P):分布式系统在遇到任何网络分区故障时,仍能够保证对外提供满足一致性或可用性的服务。
1.2 定理
CAP 定理的内容是:对于分布式系统,网络环境相对是不可控的,出现网络分区是不可 避免的,因此系统必须具备分区容错性。但系统不能同时保证一致性与可用性。即要么 CP, 要么 AP。
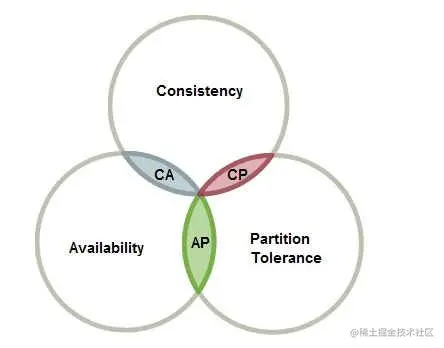
集群里面是不存在强一致性(实时一致性、严格一致性),
因为数据同步是需要时间的,没办法在A主机改变一个数据后,在B主机,C主机马上得到这个数,这个是做不到的。
可用性的有限时间内:一般搜索引擎,百度0.5秒,谷歌是0.3秒给出千万条数据认为是可用的,HAVE数据仓库,做海量级别数据查询,检索一般在20到30秒内给出检索结果就认为系统是可用的。不用的系统对优先时间的要求是不一样的。可用性的响应:响应是用户能够预测到的结果,例如百度搜索,百度告诉我没有结果,或者返回很多相关结果,都是可以预知到的,但是如果返回500错误,404都是不行的,这些都是用户预料不到的,即让用户感觉到困惑的结果是不行的。
分区容错的分区:指的是网络分区
C、A、P三者之间的冲突
假设有两台服务器,一台放着应用A和数据库V,一台放着应用B和数据库V,他们之间的网络可以互通,也就相当于分布式系统的两个部分。
在满足一致性的时候,两台服务器(假设为N1,N2)的数据是一样的,DB0=DB0。在满足可用性的时候,用户不管是请求N1或者N2,都会得到立即响应。在满足分区容错性的情况下,N1和N2有任何一方宕机,或者网络不通的时候,都不会影响N1和N2彼此之间的正常运作。
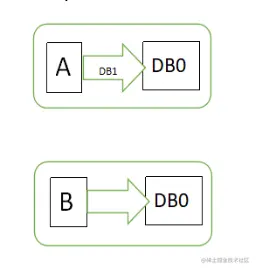
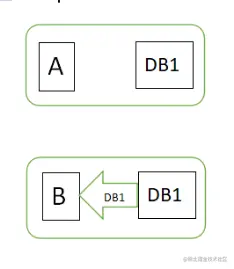
图1中,用户通过N1中的A应用请求数据更新到服务器DB0,这时N1中的服务器DB0变为DB1,通过分布式系统的数据同步更新操作,N2服务器中的数据库V0也更新为了DB1(图2),这时,用户通过B向数据库发起请求得到的数据就是即时更新后的数据DB1。
上面是正常运作的情况,但分布式系统中,最大的问题就是网络,现在假设一种极端情况,N1和N2之间的网络断开了,但我们仍要支持这种网络异常,也就是满足分区容错性,那么这样能不能同时满足一致性和可用性呢?
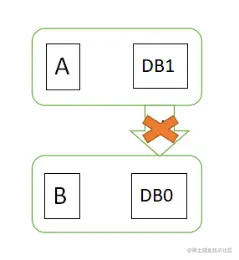
假设N1和N2之间通信的时候网络突然出现故障,有用户向N1发送数据更新请求,那N1中的数据DB0将被更新为DB1,由于网络是断开的,N2中的数据库仍旧是DB0;
如果这个时候,有用户向N2发送数据读取请求,由于数据还没有进行同步,应用程序没办法立即给用户返回最新的数据DB1,怎么办呢?有二种选择,第一,牺牲数据一致性,响应旧的数据DB0给用户;第二,牺牲可用性,阻塞等待,直到网络连接恢复,数据更新操作完成之后,再给用户响应最新的数据DB1。
为什么不能同时保证一致性与可用性?是因为数据同步是需要时间的。在同步期间,若允许 client 访问,则 client 从不同节点读取到的数据就可能是不相同的,即牺牲了一致性保证了可用性;若不允许 client 访问,则client 在同步期间无法获取服务,但一段时间后再访问系统,无论访问到的是哪个节点,读 取到的数据一定都是相同的。即牺牲了可用性保证了一致性。
1.3 BASE 理论
BASE 是 Basically Available(基本可用)、 Soft state(软状态)和 Eventually consistent(最终一致性)三个短语的简写, BASE 是对 CAP 中一致性和可用性权衡的结果,其来源于对大规模互联网系统分布式实践的结论,是基于 CAP 定理逐步演化而来的。
BASE 理论的核心思想是:即使无法做到强一致性,但每个系统都可以根据自身的业务 特点,采用适当的方式来使系统达到最终一致性。
1.3.1 基本可用
基本可用是指分布式系统在出现不可预知故障的时候,允许损失部分可用性。 即允许服 务质量下降。常见的服务质量下降有两种类型:
- 响应时间上的损失:
- 功能上的损失: 即服务降级。
1.3.2 软状态
软状态,是指允许系统数据存在的中间状态,并认为该中间状态的存在不会影响系统的 整体可用性,即允许系统主机间进行数据同步的过程存在一定延时。软状态,其实就是一种 灰度状态,过渡状态。
1.3.3 最终一致性
最终一致性强调的是系统中所有的数据副本,在经过一段时间的同步后,最终能够达到 一个一致的状态。因此,最终一致性的本质是需要系统保证最终数据能够达到一致,而不需 要实时保证系统数据的强一致性。
从一致性内容同步的时间角度来说,分为两种一致性:
- 实时一致性:只要数据发生变更,其它副本数据立即就会同步完成。在生产环境中是无法实现的,仅是一种理论状态。
- 最终一致性: 经过一段时间的同步后,最终能够达到一个一致的状态。
从 client 获取到的一致性内容角度来说,不管时间问题,分为两种一致性:
强一致性:也称为严格一致性。要求 client 访问到的数据一定是更新过的数据。弱一致性:允许 client 访问不到部分或全部更新过的数据。
1.4 ZK 与 CP
zk 遵循的是 CP 原则,即保证了一致性,但牺牲了可用性。体现在哪里呢?
当 Leader 宕机后, zk 集群会马上进行新的 Leader 的选举。但选举时长一般在 200 毫秒内,最长不超过 60 秒,整个选举期间 zk 集群是不接受客户端的读写操作的,即 zk 集群是处于瘫痪状态的。所以,其不满足可用性。
数据在做同步期间, zk 集群是对外不提供服务的,是不可用的。同步完毕, client 读取 到的一定是一致性的数据。
Eureka 是 AP 的, Consul 是 CP 的, Nacos 是 CP/AP 的。zookeeper在Dubbo里面是做注册中心的,Eureka在Spring Cloud里面也是做注册中心的。
2. 分布式事务与分布式一致性
分布式一致性一般是通过分布式事务实现的。
2.1 分布式事务
对于分布式事务,通俗地说就是, 一次操作由若干分支操作组成,这些分支操作分属不同应用,分布在不同服务器上。 分布式事务需要保证这些分支操作要么全部(或大多数) 成 功,要么全部(或大多数) 失败。
分布式系统中对于数据修改的最终确认,必须是所有(或大多数) Server 节点对本地事 务执行成功才可以。简单来说就是,若全部(或大多数)成功则成功;有一个(或大多数) 失败则失败。
在分布式事务中,协调者称为事务协调者 TC(Transaction Coordinator), Server 节点称为资源管理器 RM(Resource Manager)。
2.2 分布式一致性
客户端从分布式系统中的每一个 Server 节点中读取到的数据,在某一时间段内可以保 证都是一致的(最终一致性),那么这个系统具有分布式一致性,对外提供分布式一致性服 务。
在大量长期的生产实践探索中,涌现出了大批经典的一致性协议和算法,其中最著名的 就是 2PC、 3PC、 Paxos 与 Raft 算法。
3. 2PC
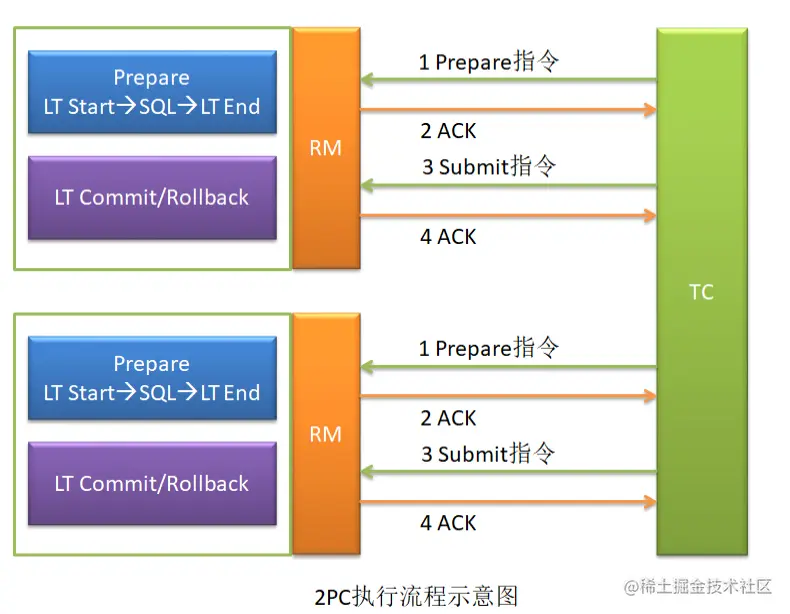
2PC, Two Phase Commit, 2 阶段提交。即在分布式系统中,每个 Server 节点对本地事务执行结果的最终确认,需要经历两个阶段: Prepare 阶段与 Commit 阶段。目前, 2PC 被广泛地应用于分布式事务解决方案中。
目前大多数由关系型数据库形成的分布式事务解决方案都是 2PC 的,例如目前最火爆的 阿里的分布式技术 Seata,其提供的 XA、 AT 及 TCC 三种模式(解决方案)都是 2PC 的。 Saga模式不是 2PC 的。
3.1 阶段一: Prepare 阶段
TC 向各个 RM 发送 Prepare 指令,这就是第一阶段提交指令。各个 RM 在接收到 Prepare指令后,首先会将修改前的数据保存到回滚日志,然后开始执行本地事务。不过,这个本地事务执行的结果对用户是不可见的。执行完毕后,将本地事务执行状态(成功或失败)上报给 TC。
3.2 阶段二: Submit 阶段
TC 保存并汇总每个 RM 上报的结果,并根据这些汇总结果向所有 RM 发出 Submit 指令, 即第二阶段提交指令。 RM 在执行完毕后,会再次将执行结果上报给 TC。
不同的 RM 汇总结果, TC 会发出不同的 Submit 指令:
- 若所有 RM 上报的本地事务执行状态为成功,则 TC 向所有 RM 发送的 Submit 指令为Commit 指令。 RM 会将数据的修改结果向用户开放。
只要有一个 RM 上报的本地事务执行状态为失败,则 TC 向所有 RM 发送的 Submit 指令为Rollback 指令。 RM 会将保存在回滚日志中的数据恢复,并向用户开放。
3.3 2PC 典型应用举例
阿里的分布式事务技术 Seata,提供了四种事务模式: XA、 AT、 TCC 与 Saga,前三种都 是 2PC 的。
3.3.1 XA 模式
XA(Unix Transaction) 是一种分布式事务解决方案,一种分布式事务处理模式,是基于 XA协议的。XA协议由Tuxedo(Transaction for Unix has been Extended for Distributed Operation,分布式操作扩展之后的 Unix 事务系统)首先提出的,并交给 X/Open 组织,作为资源管理器与事务管理器的接口标准。XA 模式架构图:
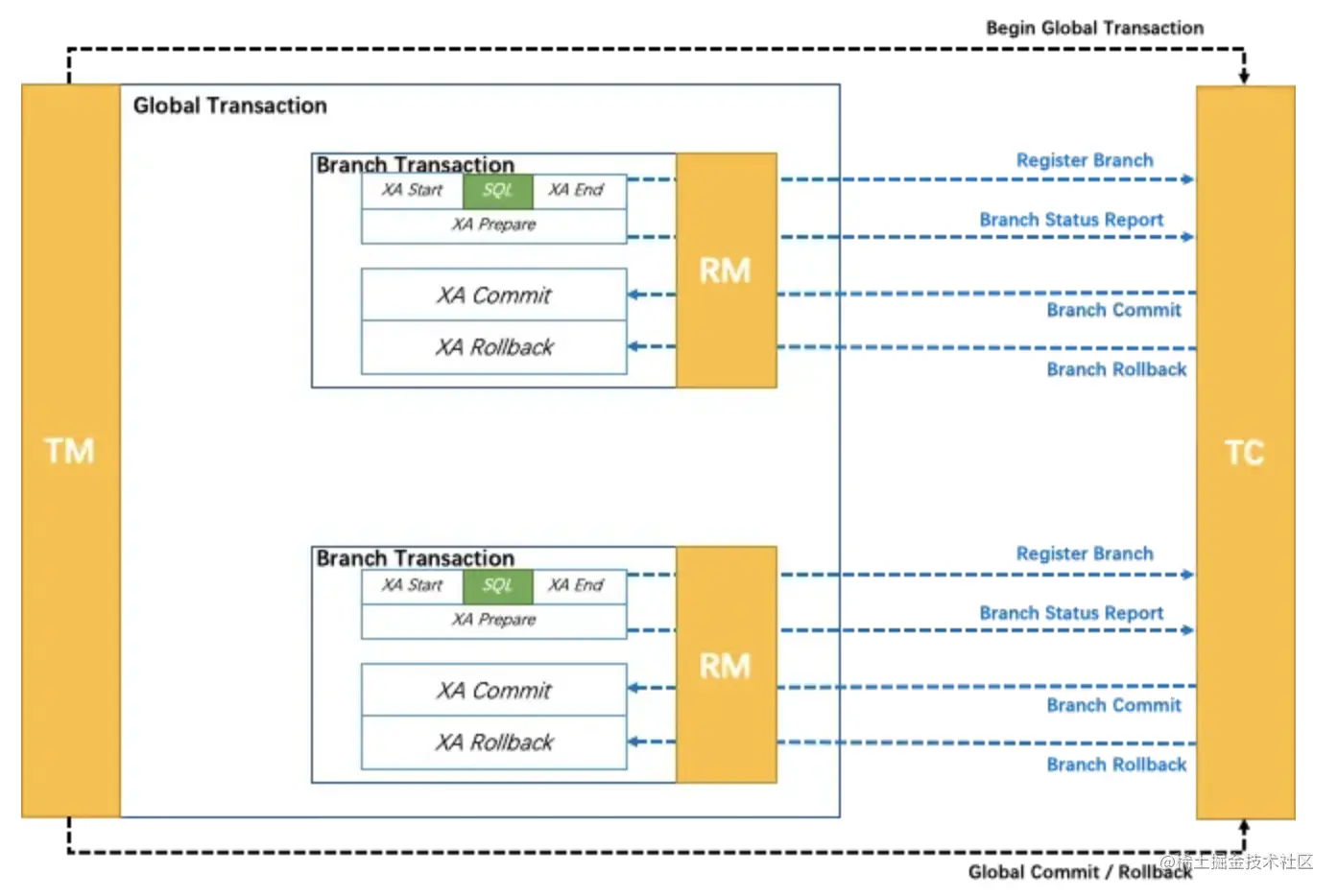
XA 模式是一个典型的 2PC,其执行原理如下:
- TM 向 TC 发起指令,开启一个全局事务。
- 根据业务要求,各个 RM 会逐个向 TC 注册分支事务,然后 TC 会逐个向 RM 发出预执行指令。
- 各个 RM 在接收到指令后会进行本地事务预执行。
- RM 将预执行结果 Report 给 TC。当然,这个结果可能是成功,也可能是失败。
- TC 在接收到各个 RM 的 Report 后会将汇总结果上报给 TM,根据汇总结果 TM 会向TC发出确认指令。
- 若所有结果都是成功响应,则向 TC 发送 Global Commit 指令。
- 只要有结果是失败响应,则向 TC 发送 Global Rollback 指令。
- TC 在接收到指令后再次向 RM 发送确认指令。
XA 模式存在两个较明显的问题:
- 当 TM 下发 Global Commit 指令后,各个 RM 中
存放的回滚日志就没有用处了,就可以清理掉了。但 XA 模式需要手动清理,无法实现自动清理。 - XA 模式存在 ABA 问题。
3.3.2 AT 模式
AT, Automatic Transaction。 AT 模式是 Seata 默认的分布式事务模型,是由 XA 模式演变而来的,通过全局锁对 XA 模式中的 ABA 问题进行了改进,并实现了回滚日志的自动清理。
AT 模式存在的问题是, prepare 阶段、 commit/rollback 阶段,及回滚日志的清理过程,完全都是自动化完成的,无法实现定制化。3.3.3 TCC 模式
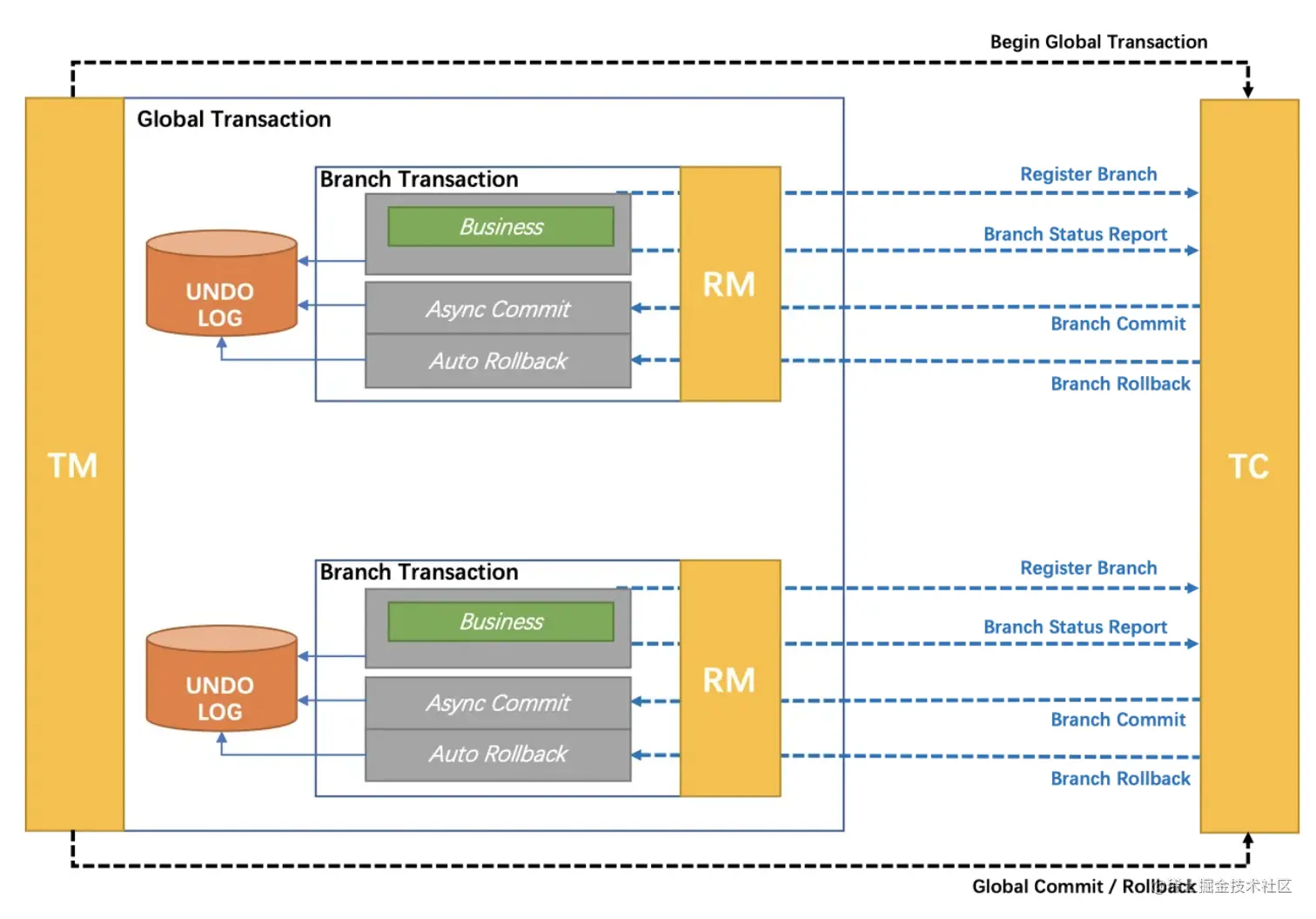
与 AT 的重要区别是,支持将自定义的分支事务纳入到全局事务管理中,即可以实现定制化的日志清理与回滚过程。当然,该模式对业务逻辑的侵入性是较大的。
3.4 2PC 的缺陷
2PC 最大的特点就是简单:原理简单,实现简单。 但却存在先天缺陷: 同步阻塞、 中心 化问题、数据不一致、太过保守、性能问题等。 不过,若实现方案设计的较好,这些缺陷是 可以弱化的。
3.4.1 同步阻塞
在一个分布式事务执行期间,若所有 RM prepare 完自己的本地事务后,就会处于阻塞 状态,等待 TC 再次发布第二阶段指令。阻塞期间, RM 中的资源是处于锁定状态的。
3.4.2 中心化问题
TC 一旦出现问题,整个系统就会崩溃。
3.4.3 数据不一致
在 TC 发送了第二阶段的 Commit 指令后,若由于网络原因,只有部分 RM 接收到了。 此时,收到 Commit 指令会将本地事务执行结果进行确认,但未收到的 RM 中的资源会一直 处于锁定状态。当自行解锁后,会通过回滚日志恢复到修改前的状态。此时就出现了不同 RM 中相同数据不同的值的情况,即数据不一致。
3.4.4 太过保守
任何一个 RM 在 Prepare 阶段执行失败,都将引发分布式事务的全局性失败。
3.4.5 性能问题
假设一个分布式事务由 n 个分支事务构成,每个分布事务的完成可能需要消耗较大的本地系统资源。当前 n-1 个分支事务全部完成并且成功后,第 n 个分支事务执行完毕,但执行 状态为失败。此时 TC 会向所有 TM 发布 Rollback 指令。
从本地事务的执行到回滚,消耗了大量的系统资源,但却没有成功,恢复到了没有执行 之前的状态。这就是一个很大的性能问题。
4. 3PC
3PC, Three Phase Commit, 3 阶段提交。即在分布式系统中,每个 Server 节点对本地事务执行结果的最终确认,需要经历三个阶段: Accept、 Prepare 与 Submit。 其实就是在 2PC的两个阶段之前又增加了一个新的阶段: Accept 阶段。
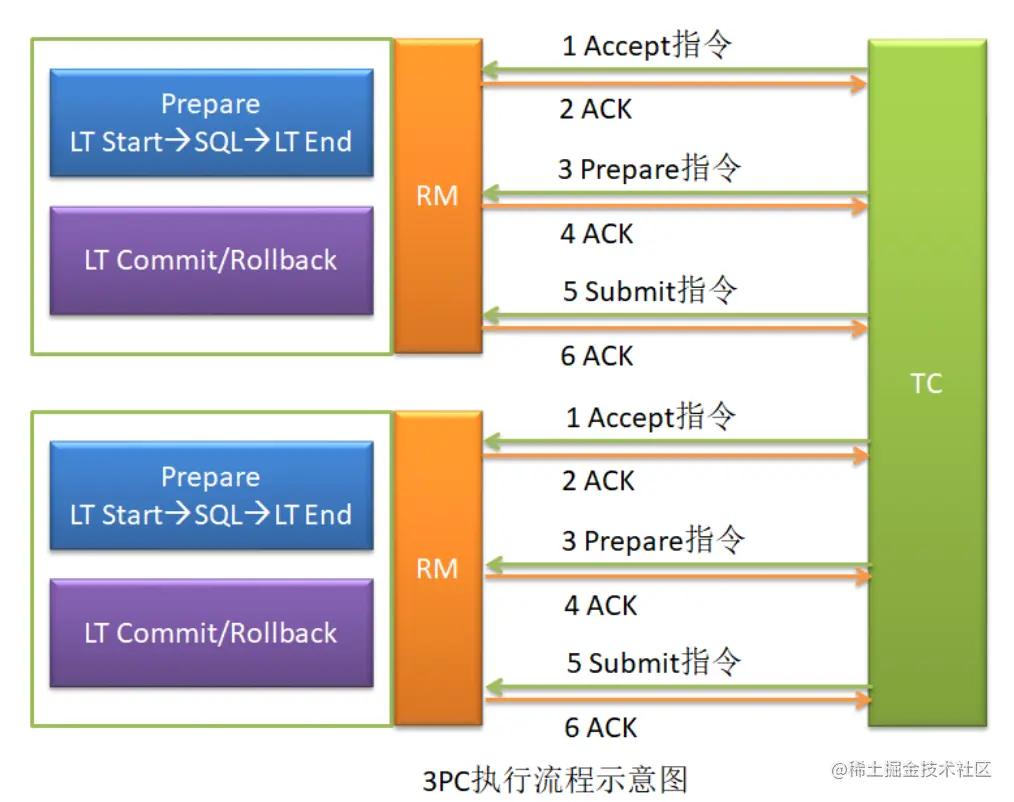
4.1 Accept 阶段
TC 向各个 RM 发送 Accept 指令,该指令中包含着事务内容。这就是第一阶段提交指令。 各个 RM 在接收到 Accept 指令后,仅对事务内容进行判断,判断其是否可以完成本事务, 并没有真正执行这个事务。并将判断结果上报给 TC。
TC 在接收到各个 RM 上报的判断结果后,根据不同的汇总结果,来决定是否继续 Prepare 阶段。
- 若所有 RM 上报的判断结果都是 Yes,则继续 Prepare 阶段。
- 只要有一个 RM 上报的判断结果是 No,则结束整个全局事务。
4.2 3PC 的缺陷
2PC 中存在的前四点缺陷,即同步阻塞、 中心化问题、数据不一致、太过保守, 3PC 中依然存在。但 3PC 解决了 2PC 中的性能问题。