17. 源码| 算法集群选举原理流程源码
前面一篇已经分析过了FLE算法各个机器间创建通信结构的流程源码,即分析原理流程的时候各个机器是可以正常的发送及接收消息的,建议在观看选举原理流程源码的时候可以了解ZK集群的FLE选举原理流程,不清楚的可以调至本篇观看了解:14.Zookeeper源码篇10-FLE(FastLeaderElection)算法集群选举通信原理及流程结构(类解读)
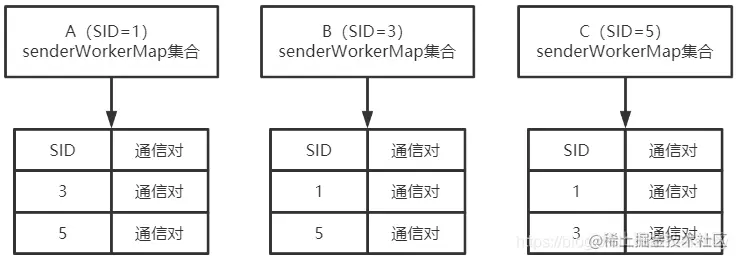
本篇将会基于源码来分析各个机器的选举状态及选举通信,依旧使用上篇的三台机器信息,且机器间的通信对是完成整可用的,机器信息如下:
- A机器:myid=1,启动时间最早;
- B机器:myid=3,启动时间在A之后;
- C机器:myid=5,启动时间最后。 且各个机器完整的通信对如下:
1. 选举机制详解
1.1 选举机制-第一次启动
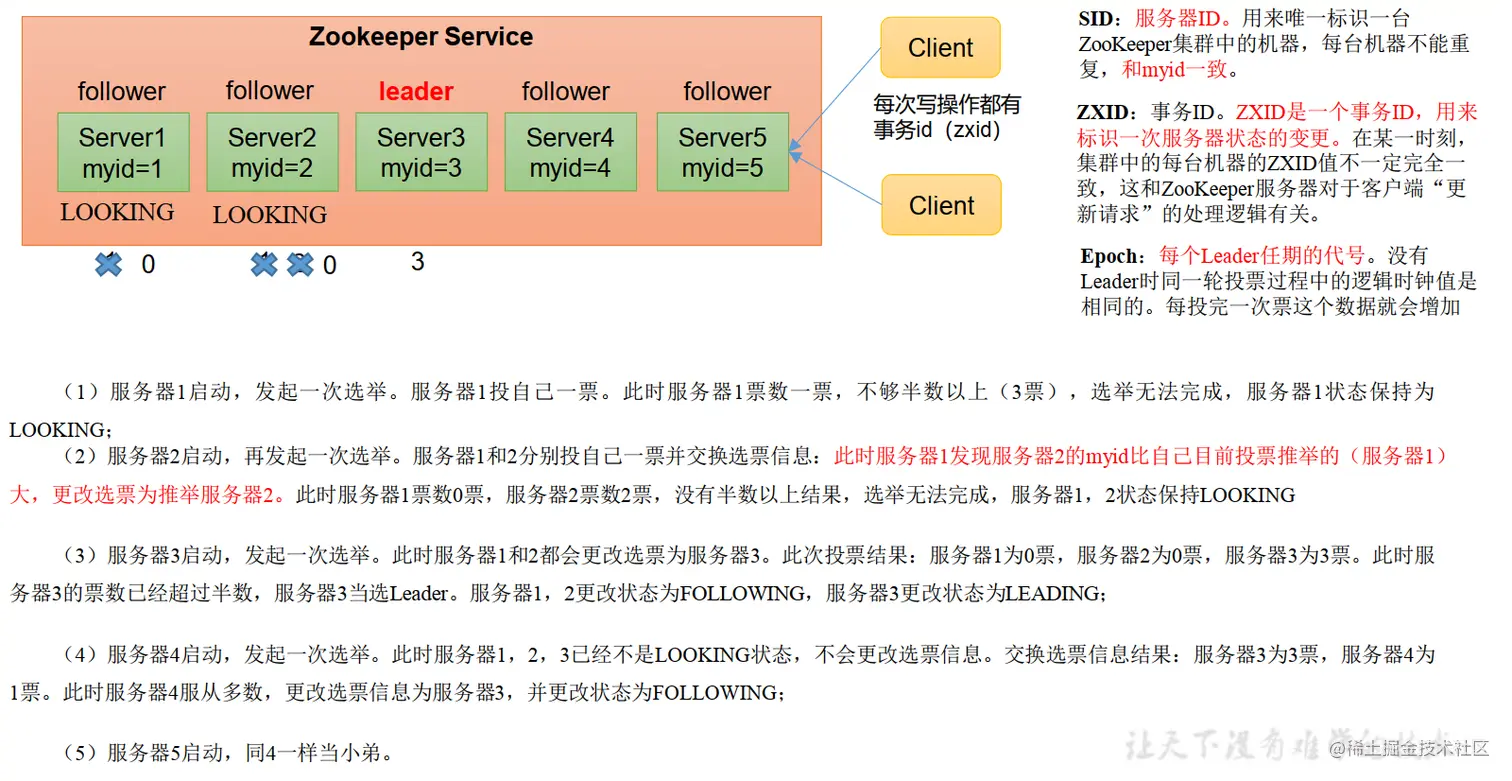
1.2 选举机制-非第一次启动

选举机制的整体流程图:
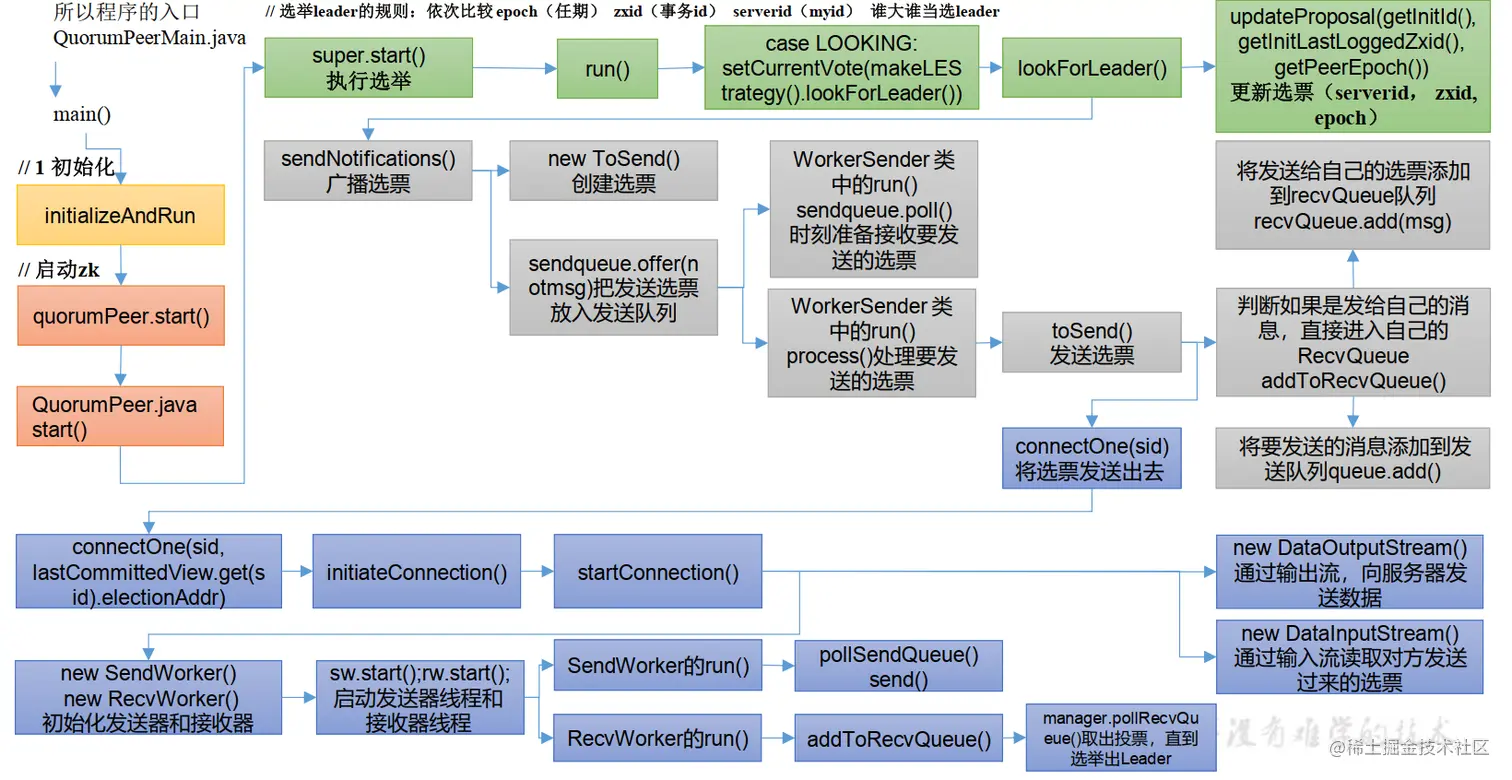
接下来便开始源码的选举原理流程分析。
2. FastLeaderElection选举发送通知
无论是刚刚启动或者是上一代的Leader退位开始选举新的Leader,各个机器在开始选举流程时的状态都是LOOKING,都会执行FastLeaderElection选举对象的公共流程。接下来便分析一下这个对象的公共流程,关键源码如下:
public class FastLeaderElection implements Election {
// 本机器的集群对象
QuorumPeer self;
// 选举流程时的逻辑迭代数,每调用一次lookForLeader进行选举时该值会+1
// 发送到其它机器上时对应Notification对象的electionEpoch属性
volatile long logicalclock;
// 本机推崇将要当选leader的myid,对应Notification对象的leader,可以看成是
// 某个机器的id
long proposedLeader;
// 本机推崇将要当选leader的zxid,对应Notification对象的zxid
long proposedZxid;
// 本机推崇将要当选leader的epoch,对应Notification对象的peerEpoch
long proposedEpoch;
// 将要使用通信对发送消息的消息存储队列集合,通信对发送消息时将会从该集合中
// 取出消息对象并使用Socket通信发送给对应的机器
LinkedBlockingQueue<ToSend> sendqueue;
public Vote lookForLeader() throws InterruptedException {
// 开始在集群内选举Leader,注册LeaderElection到JMX忽略
if (self.start_fle == 0) {
// 记录FLE算法的开始时间
self.start_fle = System.currentTimeMillis();
}
try {
// 本集合key为leaderId,value为对应id的投票信息,集合将会记录
// 本次投票的各个机器投票情况
HashMap<Long, Vote> recvset = new HashMap<Long, Vote>();
// 新加入的机器用来记录集群内其它机器的投票情况
HashMap<Long, Vote> outofelection = new HashMap<Long, Vote>();
// 每次轮询其它机器发来消息的间隔时间,固定200毫秒执行一次
int notTimeout = finalizeWait;
synchronized(this){
// 逻辑选举次数+1,代表本机器有一次执行了重新选举Leader的操作
logicalclock++;
// 投票前先把本机器的投票信息投给自己,getInitId()为本机器的
// myid值,getInitLastLoggedZxid()为本机器的zxid值
// getPeerEpoch()为本机器的currentEpoch值
updateProposal(getInitId(), getInitLastLoggedZxid(),
getPeerEpoch());
}
// 对集群内的各个机器发送消息通知,告诉他们我选举自己当选Leader
sendNotifications();
// 发完通知消息后开始轮询其它机器的消息
while ((self.getPeerState() == ServerState.LOOKING) &&
(!stop)){
// 轮询集合内是否有其它机器发来的消息
Notification n = recvqueue.poll(notTimeout,
TimeUnit.MILLISECONDS);
// 后续收到通知处理流程这里暂不分析,等分析完本机器发送完通知后
// 再逐个分析
...
}
}
}
synchronized void updateProposal(long leader, long zxid, long epoch){
// 更新本机器记录的Leader信息,投票前把这些信息改成本机器的,即先把票
// 投给自己
proposedLeader = leader;
proposedZxid = zxid;
proposedEpoch = epoch;
}
private void sendNotifications() {
// 轮询配置文件中所配置的各个Server信息,并向每台机器发送通知
for (QuorumServer server : self.getVotingView().values()) {
long sid = server.id;
// 将本机器的信息封装,并发给myid为sid的机器
ToSend notmsg = new ToSend(ToSend.mType.notification,
proposedLeader,// 第一次发送此值为本机器的myid
proposedZxid,// 第一次发送此值为本机器的zxid
logicalclock,// 第一次发送此值为本机器的logicalclock
QuorumPeer.ServerState.LOOKING,// 本机器流程为LOOKING
sid,// 目标机器的myid
proposedEpoch);// 第一次发送此值为本机器的currentEpoch
// 放入sendqueue集合中以便本选举对象的WorkerSender发送这些
// 通知消息给其它的机器
sendqueue.offer(notmsg);
}
}
}3. 通信对的SendWorker对象监听集合并发送消息
在上一篇我们已经了解了每台机器都会有集群内各个机器的通信对,而SendWorker便是负责监听集合来发送消息的线程对象,以机器A为例,在开始选举前会向集群内的其它机器(即B和C)发送我选择我自己当选Leader的消息通知,因此此时A的待发送消息队列queueSendMap集合里面一定会有发送给B和C的消息,SendWorker启动后将会发送这些消息。B和C机器一样,关键源码如下:
class SendWorker extends ZooKeeperThread {
// 本个通信对的发送线程对象需要对接通信的机器sid(即对应机器的myid)
Long sid;
// 本个通信对的发送线程对象和需要通信机器建立的Socket长连接
Socket sock;
// 本通信对的发送消息线程对象对应的接收消息线程对象
RecvWorker recvWorker;
// 运行状态
volatile boolean running = true;
// 使用Socket对象的outputStream对象流创建的数据输出流对象,负责实际的通信
DataOutputStream dout;
// 记录当前的连接管理对象中有多少个线程正在运行,即选择通信对的
// SendWorker和RecvWorker
private AtomicInteger threadCnt = new AtomicInteger(0);
// 保存给sid机器的最后发送消息,key为目标机器的sid,value则是具体的发送消息
final ConcurrentHashMap<Long, ByteBuffer> lastMessageSent;
public void run() {
// 有一个线程已经执行,线程数量+1
threadCnt.incrementAndGet();
try {
// 刚启动的时候便去queueSendMap集合中查询是否有本通信对的发送目标
// 机器消息
ArrayBlockingQueue<ByteBuffer> bq = queueSendMap.get(sid);
// 如果没有消息需要发送给目标机器则获取最后一次发送给这个机器的消息
// 并发送给目标机器
if (bq == null || isSendQueueEmpty(bq)) {
// 获取最后发送给目标机器的消息
ByteBuffer b = lastMessageSent.get(sid);
// 如果以前发送过消息则调用send()方法发送消息
if (b != null) {
// 发送消息,具体方法后面再分析
send(b);
}
}
} catch (IOException e) {
// 发生了意外则销毁本通信对
this.finish();
}
try {
while (running && !shutdown && sock != null) {
ByteBuffer b = null;
try {
// 查询queueSendMap集合中是否有本通信对的发送目标机器消息
ArrayBlockingQueue<ByteBuffer> bq = queueSendMap
.get(sid);
// 如果目标机器的阻塞队列不为空则从阻塞队列中获取需要发送的
// 消息
if (bq != null) {
// 如果队列不为空则从阻塞队列中获取数据
b = pollSendQueue(bq, 1000, TimeUnit.MILLISECONDS);
} else {
// 如果阻塞队列为空说明初始化有异常,阻塞队列在实例化
// 线程对象时就已经被创建,且容量只有1
break;
}
// 从消息阻塞队列中获取到了消息且不为空则进行发送操作,为空
// 则继续下一次轮询查询阻塞队列是否有需要发送的消息
if(b != null){
// 发送前记录给目标机器发送的最后一次消息对象,以方便
// 下次和目标机器通信时的通信对可以继续上次的消息开始
// 发送,确保消息的连续性。不用担心如果目标机器接收到
// 相同的消息会怎么办,接收方就算接收到了相同的消息
// 也不会对结果有什么影响
lastMessageSent.put(sid, b);
// 调用方法方法去发送消息对象
send(b);
}
}// 异常忽略...
}
}// 异常忽略...
// 运行完成说明该通信对已经需要退出,调用销毁方法
this.finish();
}
synchronized void send(ByteBuffer b) throws IOException {
// 为需要发送的字节数组创建新的等长度数组以方便后续进行消息校验
byte[] msgBytes = new byte[b.capacity()];
try {
// 将需要发送的消息数组位置归位,以确保可以校验整个数组
b.position(0);
// 调用get方法有两个目的:1、检查数组数据边界是否正常;
// 2、检查缓存对象中的数据是否超出缓存初始化的大小,如果超出抛异常
b.get(msgBytes);
} catch (BufferUnderflowException be) {
// 如果缓存数据超出缓存对象的申请大小则说明内存溢出,无法进行正常操作
return;
}
// 校验通过发送缓存对象中的数据,首先发送数据大小,其次再发送整体数据
dout.writeInt(b.capacity());
dout.write(b.array());
dout.flush();
}
}假设上述分析通信对的SendWorker发送线程对象为机器A的,其内部保存的sid为机器C的,即机器A的SendWorker发送通信消息给目标机器C,而机器C的通信对接收消息线程对象RecvWorker将会收到此消息并进行处理。
4. 通信对的RecvWorker对象接收消息
接着刚刚的假设逻辑走,现在A机器已经发送了消息,轮到了机器C的RecvWorker接收消息并进行相应的逻辑处理了。关键源码如下:
class RecvWorker extends ZooKeeperThread {
// 本个通信对的发送线程对象需要对接通信的机器sid(即对应机器的myid)
Long sid;
// 本个通信对的发送线程对象和需要通信机器建立的Socket长连接
Socket sock;
// 本通信对的发送消息线程对象对应的接收消息线程对象,该对象仅在需要销毁
// 本线程对象时用到finish()方法
final SendWorker sw;
// 运行状态
volatile boolean running = true;
// 使用Socket对象的outputStream对象流创建的数据输入流对象,负责实际的接收
// 消息通信
DataInputStreamd din;
// 接收目标机器发送过来的数据最大长度,最大长度为500K
static final int PACKETMAXSIZE = 1024 * 512;
@Override
public void run() {
// 有一个线程已经执行,线程数量+1
threadCnt.incrementAndGet();
try {
// 开始轮询din对象接收sid目标机器的消息
while (running && !shutdown && sock != null) {
// 接收消息需要和发送方一样,发送方在发送消息时第一步便把
// 消息的长度发送了过来,因此接收也是首先接收数据长度
int length = din.readInt();
// 如果数据长度不符合则会抛出异常退出,因此发送方才会进行必要的
// 校验,因为接收方接收到不符合规范的之后将会关闭连接通信
if (length <= 0 || length > PACKETMAXSIZE) {
throw new IOException();
}
// 从目标机器的通信Socket对象接收完整的数据
byte[] msgArray = new byte[length];
din.readFully(msgArray, 0, length);
// 封装生成对应的缓存对象ByteBuffer
ByteBuffer message = ByteBuffer.wrap(msgArray);
// 将接收到的数据添加到recvQueue集合中,recvQueue集合为
// QuorumCnxManager对象和FLE选举算法对象进行消息交互的集合
addToRecvQueue(new Message(message.duplicate(), sid));
}
} finally {
// 抛出了IO异常之后销毁本通信对并关闭Socket连接对象
sw.finish();
if (sock != null) {
// 关闭Socket连接对象
closeSocket(sock);
}
}
}
public void addToRecvQueue(Message msg) {
// 将最新需要发送的消息添加到集合中
final boolean success = this.recvQueue.offer(msg);
if (!success) {
throw new RuntimeException("Could not insert into receive queue");
}
}
}到此时两个机器间的通信对已经完成了信息交互,机器A已经把需要发送的消息发给了机器C,当然其它的机器间要进行信息交互流程和这个例子也是一样的。
5. WorkerReceiver处理通信对接收到的消息
在前面的文章分析过,FLE选举算法对象和QuorumCnxManager连接管理对象之间的消息通信是通过集合来通信的,而对集合进行操作的线程对象则是WorkerReceiver,其为FLE对象的内部类。关键源码如下:
class WorkerReceiver extends ZooKeeperThread {
// 运行状态
volatile boolean stop;
// 与其进行交互的集群连接管理对象
QuorumCnxManager manager;
// 将要使用通信对发送消息的消息存储队列集合,通信对发送消息时将会从该集合中
// 取出消息对象并使用Socket通信发送给对应的机器
LinkedBlockingQueue<ToSend> sendqueue;
// WorkerReceiver线程对象和实际的FLE选举算法对象进行通信的集合,也就是说
// FLE对象需要和QuorumCnxManager对象进行交互中间需要经过两次集合传递
// 即:QuorumCnxManager->recvQueue->WorkerReceiver->recvqueue->FLE
LinkedBlockingQueue<Notification> recvqueue;
public void run() {
Message response;
while (!stop) {
try{
// 从连接管理对象的recvQueue集合中取出通信对RecvWorker对象
// 接收并放入的消息对象
response = manager.pollRecvQueue(3000,
TimeUnit.MILLISECONDS);
// 如果经过了3s还是没查询到消息对象则继续下次轮询
if(response == null) continue;
// 如果本机器配置的参与选举机器sid不包含刚接收机器的sid则认为
// 该机器只能是follower或者observer,Leader只会在本集群中
// 最早一批的机器中产生
if(!self.getVotingView().containsKey(response.sid)){
// 取出本机器当前Leader的信息并转换成待发送的消息对象
Vote current = self.getCurrentVote();
ToSend notmsg = new ToSend(ToSend.mType.notification,
current.getId(),
current.getZxid(),
logicalclock,
self.getPeerState(),
response.sid,
current.getPeerEpoch());
// 立即向发送给本机器的sid机器回消息,通知其本集群中的
// Leader信息,如果收到消息的机器是参与选举的则会直接变成
// Follower,如果是Observer也会直接变成Observer
sendqueue.offer(notmsg);
} else {
// 如果接收到的消息小于28长度,说明可能是简单的响应或者
// 不能影响到实际选举流程的消息,退出本次轮询开始下次
if (response.buffer.capacity() < 28) {
continue;
}
// 用来兼容某些消息未发送sid机器的peerEpoch值
boolean backCompatibility =
(response.buffer.capacity() == 28);
// 让response的位置属性变成初始化状态(但数据并未删除)
response.buffer.clear();
// 创建通知对象
Notification n = new Notification();
...
// 默认状态为LOOKING,这样即使消息异常也不会造成实际的影响
QuorumPeer.ServerState ackstate =
QuorumPeer.ServerState.LOOKING;
// 从接收到的消息中取出发送消息机器的状态并在后续进行
// 相应的赋值buffer中的值信息可以在上一篇的WorkerSender
// 线程对象buildMsg()方法分析中对应上,当然也可以不用管
// 只需要知道这种获取顺序是可以准确的拿到发送消息数据即可
switch (response.buffer.getInt()) {
case 0:
ackstate = QuorumPeer.ServerState.LOOKING;
break;
case 1:
ackstate = QuorumPeer.ServerState.FOLLOWING;
break;
case 2:
ackstate = QuorumPeer.ServerState.LEADING;
break;
case 3:
ackstate = QuorumPeer.ServerState.OBSERVING;
break;
default:
continue;
}
// 从消息对象中分别获取对应的数据,需要注意的是这些数据
// 并不是sid机器的,而是sid机器认为是Leader机器的
// 打个比方:A机器现在接收到B机器发送过来的消息,B机器认为
// C机器是集群的Leadere,机器A接收到的response的值便是C
// 机器的而不是B机器的
n.leader = response.buffer.getLong();
n.zxid = response.buffer.getLong();
n.electionEpoch = response.buffer.getLong();
n.state = ackstate;
n.sid = response.sid;
// 如果消息长度不为28说明显式的把peerEpoch值传了过来
// 否则需要从发送过来的zxid中获取对应的peerEpoch值
if(!backCompatibility){
n.peerEpoch = response.buffer.getLong();
} else {
n.peerEpoch = ZxidUtils.getEpochFromZxid(n.zxid);
}
// 获取版本信息,3.4.6新增的
n.version = (response.buffer.remaining() >= 4) ?
response.buffer.getInt() : 0x0;
// 如果接收到的消息状态为LOOKING选举状态,则说明发送消息
// 的机器处于选举状态,启动时基本所有参与选举的机器都会
// 进入到这个判断中,算是选举状态的普遍性条件
if(self.getPeerState() ==
QuorumPeer.ServerState.LOOKING){
// 接收到消息后将其添加到recvqueue集合中,该集合就是
// 本对象和FLE选举对象交互的集合
recvqueue.offer(n);
// 这个条件判断是为了中途退出了集群后来又连接上来的
// 机器消息使用,消息通知的electionEpoch属性就是
// 机器sid上的logicalclock,因此这个条件可以理解成:
// 如果发送消息机器的logicalclock选举轮次要比本集群
// 中的选举轮次要低,则直接把本机器认为的可能是Leader
// 的机器信息发送给机器sid,让其跟着本集群选举走
if((ackstate == QuorumPeer.ServerState.LOOKING)
&& (n.electionEpoch < logicalclock)){
// 获取当前机器认为的Leader机器信息
Vote v = getVote();
// 转化化成待发送消息对象
ToSend notmsg = new ToSend(
ToSend.mType.notification,
v.getId(),
v.getZxid(),
logicalclock,
self.getPeerState(),
response.sid,
v.getPeerEpoch());
// 放入sendqueue集合中以便通信对的发送对象获取
sendqueue.offer(notmsg);
}
} else {
// 进入到这里说明本集群已经产生了Leader,而接受到的
// 选举消息大概率是原来在集群中,但是由于网络或者其它
// 原因导致中途退出了,而现在中途再次加入到集群中
// 先获取本集群的Leader投票信息
Vote current = self.getCurrentVote();
// 如果发送消息过来的机器处于选举状态,即原来的投票
// 信息已经失效,需要再次投票以加入到本集群中来
if(ackstate == QuorumPeer.ServerState.LOOKING){
ToSend notmsg;
// 版本处于3.4.6以上且通信正常的机器发过来的版本
// 信息都是0x1,如果是0x0只能说明发送消息过来的
// 机器版本低于3.4.6
if(n.version > 0x0) {
// 版本兼容的机器,直接使用本集群内的Leader
// 信息封装成待发送消息
notmsg = new ToSend(
ToSend.mType.notification,
current.getId(),
current.getZxid(),
current.getElectionEpoch(),
self.getPeerState(),
response.sid,
current.getPeerEpoch());
} else {
// 如果版本不兼容则使用上一次的集群投票信息
// 封装成待发送消息对象
Vote bcVote = self.getBCVote();
notmsg = new ToSend(
ToSend.mType.notification,
bcVote.getId(),
bcVote.getZxid(),
bcVote.getElectionEpoch(),
self.getPeerState(),
response.sid,
bcVote.getPeerEpoch());
}
// 添加到待发送集合中以便SendWorker通信对发送
sendqueue.offer(notmsg);
}
}
}
}// 异常忽略...
}
}
}总和看下来这个线程对象只是帮忙在FLE选举对象和QuorumCnxManager对象中间做了一层简单的过滤,过滤事件如下:
- 如果新加入的机器未在本机器的选举集群中,则直接把本机器当前的投票信息封装返回;
- 如新加入的机器参与了本机器的集群选举,则获取消息的具体内容,并进行如下判断:
- 如果本机器正在进行选举则先将消息通知添加到recvqueue集合以便FLE处理,如果发送消息过来的机器也是选举状态且选举迭代比本机器小,则直接把本机器的当前投票信息封装返回;
- 如果本机器参与的集群选举已经选出了Leader和Follower,且发送消息过来的机器还处于选举(即新加入的机器),则判断版本号,3.4.6及以上的返回当前投票信息,以下的则返回上一次的投票信息。
6. FastLeaderElection对象处理集群响应消息
在上一篇我们分析过FLE对象,在调用lookForLeader()方法时会给所有的机器发送一个选举为自己当选Leader的通知,本次分析选举流程便从这个地方开始。关键源码如下:
public class FastLeaderElection implements Election {
// 本机器的集群对象
QuorumPeer self;
// 选举流程时的逻辑迭代数,每调用一次lookForLeader进行选举时该值会+1
// 发送到其它机器上时对应Notification对象的electionEpoch属性
volatile long logicalclock;
// 本机推崇将要当选leader的myid,对应Notification对象的leader,可以看成是
// 某个机器的id
long proposedLeader;
// 本机推崇将要当选leader的zxid,对应Notification对象的zxid
long proposedZxid;
// 本机推崇将要当选leader的epoch,对应Notification对象的peerEpoch
long proposedEpoch;
/**
* 翻译:开启新一轮的Leader选举。无论何时,只要我们的QuorumPeer的
* 状态变为了LOOKING,那么这个方法将被调用,并且它会发送notifications
* 给所有其它的同级服务器。
*
* 这个方法就是选举的核心方法!!!!!!!!后面专门讲解这个方法
*/
public Vote lookForLeader() throws InterruptedException {
// ------------ 1 创建选举对象,做选举前的初始化工作 ---------------------
try {
// self为当前参与选举的server对象自己
self.jmxLeaderElectionBean = new LeaderElectionBean();
MBeanRegistry.getInstance().register(self.jmxLeaderElectionBean, self.jmxLocalPeerBean);
} catch (Exception e) {
LOG.warn("Failed to register with JMX", e);
self.jmxLeaderElectionBean = null;
}
// 记录FLE算法的开始时间
self.start_fle = Time.currentElapsedTime();
try {
/*
* The votes from the current leader election are stored in recvset. In other words, a vote v is in recvset
* if v.electionEpoch == logicalclock. The current participant uses recvset to deduce on whether a majority
* of participants has voted for it.
*/
// 本集合key为leaderId,value为对应id的投票信息,集合将会记录
// 本次投票的各个机器投票情况
// recvset,receive set,用于存放来自于外部的选票,一个entry代表一次投票
// key为投票者的serverid,value为选票
// 该集合相当于投票箱
Map<Long, Vote> recvset = new HashMap<Long, Vote>();
/*
* The votes from previous leader elections, as well as the votes from the current leader election are
* stored in outofelection. Note that notifications in a LOOKING state are not stored in outofelection.
* Only FOLLOWING or LEADING notifications are stored in outofelection. The current participant could use
* outofelection to learn which participant is the leader if it arrives late (i.e., higher logicalclock than
* the electionEpoch of the received notifications) in a leader election.
*/
// outofelection,out of election,退出选举
// 其中存放的是非法选票,即投票者的状态不是looking
Map<Long, Vote> outofelection = new HashMap<Long, Vote>();
// 每次轮询其它机器发来消息的间隔时间,固定200毫秒执行一次
int notTimeout = minNotificationInterval;
// ------------ 2 将自己作为初始Leader通知给大家 ---------------------
synchronized (this) {
// 逻辑选举次数+1,代表本机器有一次执行了重新选举Leader的操作
logicalclock.incrementAndGet();
// 投票前先把本机器的投票信息投给自己,getInitId()为本机器的
// myid值,getInitLastLoggedZxid()为本机器的zxid值
// getPeerEpoch()为本机器的currentEpoch值
updateProposal(getInitId(), getInitLastLoggedZxid(), getPeerEpoch());
}
LOG.info(
"New election. My id = {}, proposed zxid=0x{}",
self.getId(),
Long.toHexString(proposedZxid));
// 对集群内的各个机器发送消息通知,告诉他们我选举自己当选Leader
// 此时各个机器的通信对已经创建完毕,因此可以将消息发送给集群内的
// 各个机器,结果为A->B、A->C通知A当选Leader,B->A,B->C通知B当选
// Leader,C->B、C->A通知C当选Leader,例子中的三台机器每台机器都
// 会向集群内其它两台机器发送当选本机器为Leqader的消息通知,当然
// 也会通知自己,但是通知自己不会经过网络通信
sendNotifications();
SyncedLearnerTracker voteSet = null;
// ------------ 3 验证自己的选票与大家的选票谁更适合做Leader ------
/*
* Loop in which we exchange notifications until we find a leader
*/
// 发完通知消息后开始轮询其它机器的消息
while ((self.getPeerState() == ServerState.LOOKING) && (!stop)) {
/*
* Remove next notification from queue, times out after 2 times
* the termination time
*/
// 轮询集合内是否有其它机器发来的消息,在本次三台机器的集群中,
// recvqueue.poll()方法一定可以轮询出三个响应消息,其中一个
// 消息通知为本系统在前面的sendNotifications()方法发出的,没
// 经过网络通信,而是直接放在了本机的集合中等待处理
Notification n = recvqueue.poll(notTimeout, TimeUnit.MILLISECONDS);
/*
* Sends more notifications if haven't received enough.
* Otherwise processes new notification.
*/
// poll执行时间超过了200毫秒,阻塞轮询返回结果为空,
if (n == null) {
// 引发外来通知为null的情况有两种,不同情况有不同的处理方案:
// manager.haveDelivered()
// 为true,说明当前server与集群没有失联
// 为false,说明当前server与集群失联
if (manager.haveDelivered()) {
// 将自己的推荐情况再次向所有其它server发送,以期待其它server
// 再次向当前server发送它们的通知
sendNotifications();
} else {
// 与集群中的其它server进行重新连接
// 问题:重连后,为什么没有再次调用sendNotifications()向其它Server发送自己的推荐情况?
// 两个原因:
// 1)队列中的元素会重新发送
// 2)只要我失联了,那么其它server就一定不会收齐外来的通知(缺少我的),若在没有收齐的情况
// 下还无法选举出新的leader,那么其它server就会出现manager.haveDelivered()为true的情况,
// 那么,其它server就会向我发送通知。我只坐等接收即可。
manager.connectAll();
}
/*
* Exponential backoff
*/
// 使下次轮询的等待时间翻倍,轮询等待时间再怎么翻倍也不能超过60000,最多为60s
notTimeout = Math.min(notTimeout << 1, maxNotificationInterval);
if (self.getQuorumVerifier() instanceof QuorumOracleMaj
&& self.getQuorumVerifier().revalidateVoteset(voteSet, notTimeout != minNotificationInterval)) {
setPeerState(proposedLeader, voteSet);
Vote endVote = new Vote(proposedLeader, proposedZxid, logicalclock.get(), proposedEpoch);
leaveInstance(endVote);
return endVote;
}
LOG.info("Notification time out: {} ms", notTimeout);
// 验证选票(验证选举人与被选举人的身份)
} else if (validVoter(n.sid) && validVoter(n.leader)) {
/*
* Only proceed if the vote comes from a replica in the current or next
* voting view for a replica in the current or next voting view.
*/
// 判断收到消息的状态,如LOOKING、Leading、Following等
switch (n.state) {
case LOOKING:
if (getInitLastLoggedZxid() == -1) {
LOG.debug("Ignoring notification as our zxid is -1");
break;
}
if (n.zxid == -1) {
LOG.debug("Ignoring notification from member with -1 zxid {}", n.sid);
break;
}
// If notification > current, replace and send messages out
// 收到的消息状态为选举中
// 如果发送过来的消息选举迭代次数大于本机的选举迭代次数
// 则说明开始需要同步迭代次数并回到正常选举流程
if (n.electionEpoch > logicalclock.get()) {
// 将消息的选举迭代赋值给本机器的,保证集群内的各个
// 机器选举迭代次数一致
logicalclock.set(n.electionEpoch);
// 清空本机器接收到的各个机器投票情况集合
recvset.clear();
// 判断发送投票消息的机器与本机器的投票信息
// 判断规则逻辑在前面已经说过了假设消息是机器B
// 发给机器C的,可以判断出C胜出,因为C的myid大
// 因此发送过来的消息对象判断失败
// totalOrderPredicate()具体判断规则在最后会
// 贴出来
if (totalOrderPredicate(n.leader, n.zxid, n.peerEpoch, getInitId(), getInitLastLoggedZxid(), getPeerEpoch())) {
// 如果发送过来的消息机器投票信息判断成功
// 则把本机的投票信息改成消息的投票信息
updateProposal(n.leader, n.zxid, n.peerEpoch);
} else {
// 如果本机器胜出,则把投票信息改成本机的
updateProposal(getInitId(), getInitLastLoggedZxid(), getPeerEpoch());
}
// 向集群内的各个机器发送本机器的投票信息
sendNotifications();
} else if (n.electionEpoch < logicalclock.get()) {
LOG.debug(
"Notification election epoch is smaller than logicalclock. n.electionEpoch = 0x{}, logicalclock=0x{}",
Long.toHexString(n.electionEpoch),
Long.toHexString(logicalclock.get()));
// 如果是通过WorkerReceiver对象发送进来的这种
// 情况在WorkerReceiver接收到时就已经处理过了
break;
} else if (totalOrderPredicate(n.leader, n.zxid, n.peerEpoch, proposedLeader, proposedZxid, proposedEpoch)) {
// 最后一种情况就是n.electionEpoch==logicalclock
// 此时说明集群内正在进行正常的选举,一切以正常的
// 规则来判断,以经常举例的A、B、C三台机器来说,
// 如果是第一次投票,一定会选举机器C来当选Leader
// 因此如果是A、B、C这种情况本机器将会把Leader信息
// 改成机器C的信息
updateProposal(n.leader, n.zxid, n.peerEpoch);
// 向集群内的其它机器发送本机器投票信息
sendNotifications();
}
LOG.debug(
"Adding vote: from={}, proposed leader={}, proposed zxid=0x{}, proposed election epoch=0x{}",
n.sid,
n.leader,
Long.toHexString(n.zxid),
Long.toHexString(n.electionEpoch));
// don't care about the version if it's in LOOKING state
// 在本机器记录sid对应的机器投票情况,比如最终A和B肯定
// 会把票投给机器C,因此到最后该集合的存储情况会如下:
// 机器A:key:sid=1,value:值为机器C的投票信息
// 机器B:key:sid=3,value:值为机器C的投票信息
// 机器C:key:sid=5,value:值为本机器的投票信息
recvset.put(n.sid, new Vote(n.leader, n.zxid, n.electionEpoch, n.peerEpoch));
// ------------ 4 判断本轮选举是否应该结束 ---------------------
// 票箱每变化一次,就会创建一次这个选票跟踪器
// 注意其两个实参:一个是当前的票箱,一个是当前的server推荐信息构成的选票
voteSet = getVoteTracker(recvset, new Vote(proposedLeader, proposedZxid, logicalclock.get(), proposedEpoch));
// hasAllQuorums方法的作用便是判断recvset集合中是
// 有一半以上的值为实例化的Vote对象信息,简单来说就是
// 在本机器判断集群内的投票信息是否已有某台机器得票率
// 过半了,如果Vote对象的投票过半则说明Leader已经
// 选举了出来
// 判断当前场景下leader选举是否可以结束了
// 当前场景:1)当前票箱 2)当前动态配置
if (voteSet.hasAllQuorums()) {
// Verify if there is any change in the proposed leader
// 轮询recvqueue集合是否还有新的消息可以接收
// 为什么这里还需要设置一个循环来轮询recvqueue集
// 合呢?这是因为只要执行到这里那么前面一定会更新
// 本机器的Leader信息并且向集群的其它机器发送本
// 机器的投票信息,此时恰好本机器已经投出了
// Leader信息,因此这里需要等待刚刚发出去的消息
// 回应收到了
while ((n = recvqueue.poll(finalizeWait, TimeUnit.MILLISECONDS)) != null) {
// 在确认集群内的其它机器消息时发现有一台机器
// 比现在的Leader机器更适合当领导则会退出
// 本次循环并且将该通知放入到recvqueue集合
// 中以便下次轮询可以查找出来
if (totalOrderPredicate(n.leader, n.zxid, n.peerEpoch, proposedLeader, proposedZxid, proposedEpoch)) {
// 放入recvqueue集合并退出循环
recvqueue.put(n);
break;
}
}
/*
* This predicate is true once we don't read any new
* relevant message from the reception queue
*/
// 如果前面有更适合的Leader则n对象一定不为空,这
// 个if判断将不会进去;而如果n为空则说明各个机器
// 的回应是没有更适合的Leader信息的,在本机器投票
// 成功出来的Leader信息完全可以胜任当选的
if (n == null) {
// 确认Leader后设置本机器的状态,如果投票的
// 机器sid和本机器相等说明本机器就是Leader,
// 如果不是则设置成Follower(learningState
// 是支持设置成Observer的,单在这里不可能)
setPeerState(proposedLeader, voteSet);
// 将Leader信息封装成Vote对象
Vote endVote = new Vote(proposedLeader, proposedZxid, logicalclock.get(), proposedEpoch);
// 进入方法打印Leader信息并清空recvqueue集合
leaveInstance(endVote);
// 返回最终的投票信息,执行到这里说明本机器
// 参与的选举流程已经结束了,本机器要么作为
// Follower要么作为Leader
return endVote;
}
}
break;
// ------------ 5 无需选举的情况 ---------------------
// 若当前通知是由Observer发来的,则直接结束当前switch-case,
// 然后再获取下一个通知。不过,正常情况下,server是不会收到
// observer的通知的。这里的代码仅是为了安全考虑的
case OBSERVING:
LOG.debug("Notification from observer: {}", n.sid);
// 如果是观察者则不用做任何事
break;
case FOLLOWING:
/*
* To avoid duplicate codes
* */
// todo
Vote resultFN = receivedFollowingNotification(recvset, outofelection, voteSet, n);
if (resultFN == null) {
break;
} else {
return resultFN;
}
case LEADING:
/*
* In leadingBehavior(), it performs followingBehvior() first. When followingBehavior() returns
* a null pointer, ask Oracle whether to follow this leader.
* */
// 如果接收到的消息是由Leader或者Follower发过来的
// 在同一个选举迭代数中说明是一起选举的,并且本机器
// 由于通信晚的原因未能在集群刚好过半的机器中,即未能
// 成为第一批修改机器状态的机器,后来收到已经改变状态
// 机器的消息时便会进入到这里
Vote resultLN = receivedLeadingNotification(recvset, outofelection, voteSet, n);
if (resultLN == null) {
break;
} else {
return resultLN;
}
default:
LOG.warn("Notification state unrecognized: {} (n.state), {}(n.sid)", n.state, n.sid);
break;
}
} else {
if (!validVoter(n.leader)) {
LOG.warn("Ignoring notification for non-cluster member sid {} from sid {}", n.leader, n.sid);
}
if (!validVoter(n.sid)) {
LOG.warn("Ignoring notification for sid {} from non-quorum member sid {}", n.leader, n.sid);
}
}
}
return null;
} finally {
try {
if (self.jmxLeaderElectionBean != null) {
MBeanRegistry.getInstance().unregister(self.jmxLeaderElectionBean);
}
} catch (Exception e) {
LOG.warn("Failed to unregister with JMX", e);
}
self.jmxLeaderElectionBean = null;
LOG.debug("Number of connection processing threads: {}", manager.getConnectionThreadCount());
}
}
}在lookForLeader()方法中如果返回了Vote对象说明本机器选举Leader的任务已经结束了,各个机器陆陆续续的修改自身状态并确定自身角色。在例子A、B、C机器中最终将会选举sid最大的C当选Leader,其余的两台机器都会是Follower。
接下来我们开始分析真正执行选举逻辑的方法lookForLeader(): 整个选举代码,我们拆成3大部分讲解 :
- 选举前的准备工作
- 将自己作为初始leader投出去
- 循环交换投票直至选出Leader,
- 判断本轮选举是否应结束
- 其实在每次验证过谁更适合做 Leader 后,就会马上判断当前的选举是否可以结束了,即当前主机所推荐的这个选票是否过半了。若过半了,则直接完成后续的一些收尾工作,例如清空选举过程中所使用的集合,以备下次使用;再例如,生成最终的选票,以备其它 Server来同步数据。若没有过半,则继续从队列中读取出下一个来自于其它主机的选票,然后进行验证。
- 无需选举的情况
- 对一些特殊情况的处理
6.1 选举前的准备工作
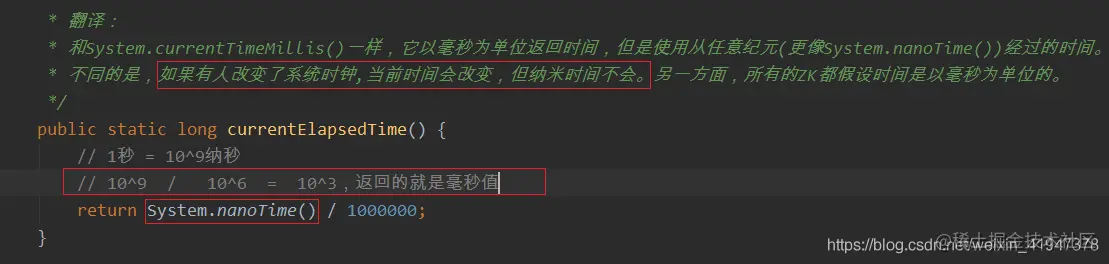
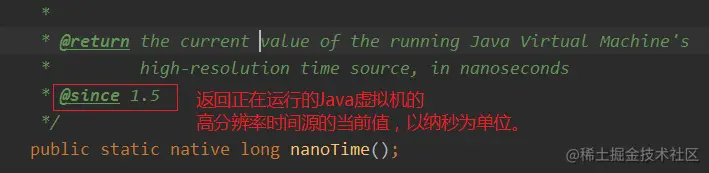
self.start_fle = Time.currentElapsedTime();为什么不用System.currentTimeMillis()?因为系统时间是可以改的,不安全,并且系统时间返回的是毫秒,而currentElapsedTime是纳秒,更精确
image.png 获取相对于虚拟机的时间,就不会有系统时间的问题
image.png
HashMap<Long, Vote> recvset = new HashMap<Long, Vote>();
- receive set,用于存放来自于外部的选票,一个entry代表一次投票
- key为投票者的serverid,value为选票Vote
- 该集合相当于投票箱,票箱记录了集群中其他节点的投票结果
HashMap<Long, Vote> outofelection = new HashMap<Long, Vote>();
- out of election,退出选举
- 其中存放的是非法选票,已经退出选举的Server发来的选票,即投票者的状态不是looking
int notTimeout = finalizeWait;
- notification Timeout,通知超时时间,200毫秒
- 发出选票后收到回复允许等待的时间
6.2 将自己作为初始leader投出去
logicalclock.incrementAndGet();逻辑时钟加一
image.png 逻辑时钟可以这么理解:logicalclock代表选举逻辑时钟(类比现实中的第十八次全国人大、第十九次全国人大……),这个值从0开始递增,在同一次选举中,各节点的值基本相同,也有例外情况,比如在第18次选举中,某个节点A挂了,其他节点完成了Leader选举,但没过多久,该Leader又挂了,于是进入了第19次Leader选举,同时节点A此时恢复,加入到Leader选举中,那么节点A的logicallock为18,而其他节点的logicallock为19,针对这种情况,节点A的logicallock会被直接更新为19并参与到第19次Leader选举中。
updateProposal(getInitId(), getInitLastLoggedZxid(), getPeerEpoch());
- 更新当前server的推荐信息为当前server自己,注意该方法和logicalclock.incrementAndGet()一起是一个原子操作
getInitId():获取当前server的id
- 判断当前状态是否是参与者,即排除了观察者,不具有选举权的Server
- 具有选举权的Server在有Leader情况下才是Follower,在选举的情况下叫Participant,参与者
getInitLastLoggedZxid():获取当前server最后的(也是最大的)zxid,即事务Id
getPeerEpoch():获取当前server的epoch
sendNotifications();
- 将更新过的Ledaer推荐信息发送出去(将更新过的信息写入到一个发送队列,具体的发送逻辑不在这,上一章讲过,有专门的线程去处理)
- 遍历的是什么?
- self.getVotingView().values(),返回的是所有具有选举权和被选举权的Server
ToSend notmsg = new ToSend(…)
- notification msg,通知消息,即将推荐的Leader信息封装成ToSend对象放入发送队列,有专门线程去发送该消息
- sid代表了消息接收者的server id

6.3 循环交换投票直至选出Leader
将自己作为初始leader投出去以后,接下来就会一直循环处理接收到的选票信息:
while ((self.getPeerState() == ServerState.LOOKING) && (!stop)){
- 循环交换通知,直到找到Leader(一但找到Leader,状态就不在是LOOKING)
Notification n = recvqueue.poll(notTimeout,TimeUnit.MILLISECONDS);
- receive queue,其中存放着接受到的所有外来的通知
- 有专门线程去处理接收其他Server发来的通知,并将接收到的信息解析封装成Notification 放入recvqueue队列
可以看到会有从recvqueue取出通知为空的情况
什么情况取出来是空呢? 假如广播出去8个,由于网络原因可能只收到3个,第四次取的时候就是空的 还有可能收到8个了,但是选举还没结束,再次取的时候也是空的 总之就是为了保证选举还没结束的时候,能继续收到其他Server的选票,并继续处理判断,直到选出Leader
if(manager.haveDelivered()){ //简单来说该方法就是判断是否和集群失联,返回false表示失联
- manager:QuorumCnxManager,连接管理器,维护了服务器之间的TCP连接
- haveDelivered:判断是否已经被交付,即检查所有队列是否为空,表示所有消息都已传递。
- queueSendMap就是之前说的连接管理器维护的发送给其他Server失败的消息副本的Map。只要有一个队列为0就返回true,后面就不看了,因为之前说过只要有一个队列为空,就说明当前Server与zk集群的连接没有问题
- 只有当所有队列都不为空,才说明当前Server与zk集群失联
sendNotifications();
- 如果manager.haveDelivered()返回true,表明当前Server和集群连接没有问题,所以重新发送当前Server推荐的Leader的选票通知,目的是为了重新再接收其他Server的回复
manager.connectAll();
如果manager.haveDelivered()返回false,表明当前Server和集群已经失联,所以重新连接zk集群中的每一个server
为什么重连了,不需要重新发送通知了呢?
因为我失联了,但是发送队列中的消息是还再的,重新连接后会重新继续发送,而且其他Server在recvqueue.poll为null的时候,如果没有和集群失联,也会重新>sendNotifications,所以这里是不需要的。
int tmpTimeOut = notTimeout*2; notTimeout = (tmpTimeOut < maxNotificationInterval?tmpTimeOut : maxNotificationInterval);
- 重新发送通知或者重连集群后,将通知超时时间扩大两倍,如果超过最大通知时间,将超时时间置为最大时间
else if(validVoter(n.sid) && validVoter(n.leader)) {
- 如果从recvqueue取出的投票通知不为空,会先验证投票的发送者和推荐者是否合法,合法了再继续处理
6.3.1 收到的投票发送者状态为LOOKING:
6.3.1.1 验证自己与大家的投票谁更适合做leader
n.electionEpoch:外来通知所在选举的逻辑时钟 logicalclock.get():获取到当前server选举的逻辑时钟
正常情况,在选举的时候每一个Server的electionEpoch应该都是相同的,即他们是在同一轮选举,是通过当前currentEpoch+1获得的,不是同步获得的。也有例外情况,比如在第18次选举中,某个节点A挂了,其他节点完成了Leader选举,但没过多久,该Leader又挂了,于是进入了第19次Leader选举,同时节点A此时恢复,加入到Leader选举中,那么节点A的logicallock为18,而其他节点的logicallock为19,针对这种情况,节点A的logicallock会被直接更新为19并参与到第19次Leader选举中。
这个时候需要比较选票所在的选举的逻辑时钟和当前Server选举的逻辑时钟是否相等,通过比较n.electionEpoch和 logicalclock.get()的值,有三种情况:
什么情况外来投票大,或者小呢?比如5个机器,已经选举好Leader了,有两个已经通知了,另外两个不知道,这个时候刚上任的Leader又突然挂了,还没通知到另外两个机器的时候,就会造成这种情况,
已经通知的那两个epoch会再次重新选举的,逻辑时钟会再加一,即epoch会在加一,未通知的那两个epoch还没变
- 站在未通知的Server角度,在接收到已经通知的Server回复的时候,就会发现回复的通知epoch更大
- 站在已经通知的Server角度,在接受到未通知的Server发来的通知时,会发现自己比通知的epoch大
if (n.electionEpoch > logicalclock.get()) {…}
- 处理n.electionEpoch 比 logicalclock.get() 大的情况(外来投票epoch大)
- 自己已经过时了,选谁都没有意义,所以做如下操作:
- logicalclock.set(n.electionEpoch):更新当前server所在的选举的逻辑时钟
- recvset.clear():清空票箱,之前收集的投票都已经过时了,没意义了。
- totalOrderPredicate(n.leader, n.zxid, n.peerEpoch, getInitId(), getInitLastLoggedZxid(), getPeerEpoch()):判断外来n与当前server谁更适合做新的leader(注意不是当前Server所推荐的,而就是当前Server)
- updateProposal(…):选择更适合的更新当前server的推荐信息
- sendNotifications():将自己的选票广播出去
else if (n.electionEpoch < logicalclock.get()) {…}
- 处理n.electionEpoch 比 logicalclock.get() 小的情况(外来投票epoch小)
- 说明外来的过时了,它的选票没有意义,不做任何处理,直接break掉switch,重新进入循环,从recvqueue取下一个通知,继续处理
else if (totalOrderPredicate(n.leader, n.zxid, n.peerEpoch, proposedLeader, proposedZxid, proposedEpoch)) {…}
- 处理n.electionEpoch 与 logicalclock.get() 相等的情况,即他们在同一轮选举中
- totalOrderPredicate(…):断言,判断外来n与当前server所推荐的leader谁更适合做新的leader,返回true,则n(外来的)更适合
- 如果返回true,即外来的更合适,则执行下面方法:
- updateProposal():更新当前server的推荐信息
- sendNotifications():广播出去 处理完上面情况后,如果没有break,即是外来选票的逻辑时钟更大,或者相等,代表外来选票有效,则将选票放入选票箱:
recvset.put(n.sid, new Vote(n.leader, n.zxid, n.electionEpoch, n.peerEpoch));
- 将外来n通知封装为一个选票,投放到“选票箱”
特殊情况:当前服务器收到外来通知发现外来通知推荐的leader更适合以后,会更新自己的推荐信息并再次广播出去,这个时候recvqueue除了第一次广播推荐自己收到的回复外,还会收到新一轮广播的回复,对于其他Server而言有可能会回复两次通知,但对于本地Server是没有影响的,因为投票箱recvset是一个Map,key是发送消息的服务器的ServerId,每个Server只会记录一个投票,新的会覆盖旧的
接下来会尝试走《3.1.2 判断本轮选举是否可以结束了》这一步,但是如果刚开始选举,要达到相同选票过半才结束选举,所以肯定不会结束,里面的逻辑是不会走的,所以直接break掉switch,然后会循环到一开始从recvqueue取下一个通知,继续处理…
- totalOrderPredicate(n.leader, n.zxid, n.peerEpoch,proposedLeader, proposedZxid, proposedEpoch)
- totalOrderPredicate(n.leader, n.zxid, n.peerEpoch,getInitId(), getInitLastLoggedZxid(), getPeerEpoch())
- 判断谁更适合做leader
- 该方法返回true,表示外来的更适合,即new更适合
- 判断谁更适合做leader
6.4 判断本轮选举是否可以结束了
终止断言:判断当前Server所推荐的leader在票箱中的支持率是否过半
// 验证当前Leader选举是否可以结束了
public boolean hasAllQuorums() {
// 遍历所有的QuorumVerifier,只有当所有QuorumVerifier
// 中的ackset都判断过半了,才能结束本轮leader选举。
for (QuorumVerifierAcksetPair qvAckset : qvAcksetPairs) {
if (!qvAckset.getQuorumVerifier().containsQuorum(qvAckset.getAckset())) {
// 只要有一个QuorumVerifier中的ackset没有过半,就不能结束选举
return false;
}
}
// 选举可以结束了
return true;
}
/**
* Verifies if a given set is a quorum.
* 验证给定的set是否是大多数
*/
public boolean containsQuorum(Set<Long> set) {
// 临时集合变量
// key为groupId,value为当前set中该groupId的所有server的weight之和
HashMap<Long, Long> expansion = new HashMap<Long, Long>();
/*
* Adds up weights per group
*/
LOG.debug("Set size: {}", set.size());
if (set.size() == 0) {
return false;
}
for (long sid : set) {
// 获取当前遍历的server所属的groupId
Long gid = serverGroup.get(sid);
if (gid == null) {
continue;
}
// 若当前expansion中没有该gid,那么当前遍历的这个server就是这个group的第一个server,
// 就将当前遍历server的weight作为该group的权重之和写入expansion
if (!expansion.containsKey(gid)) {
expansion.put(gid, serverWeight.get(sid));
} else {
// 若当前expansion中已经存在这个gid了,那么就将当前遍历server的weight追加到这个
// group的weight之和中
long totalWeight = serverWeight.get(sid) + expansion.get(gid);
expansion.put(gid, totalWeight);
}
}
/*
* Check if all groups have majority
*/
int majGroupCounter = 0;
for (Entry<Long, Long> entry : expansion.entrySet()) {
// 获取当前遍历的group
Long gid = entry.getKey();
LOG.debug("Group info: {}, {}, {}", entry.getValue(), gid, groupWeight.get(gid));
// entry.getValue() 是当前遍历group的totalWeight
// 判断当前遍历group的totalWeight是否大于当前组总权重之和的一半,
// 若大于,计数器加一
if (entry.getValue() > (groupWeight.get(gid) / 2)) {
majGroupCounter++;
}
}
// 若大多数group都满足前面的条件,则返回true,
// 表示当前版本的QuorumVerifier对ackset的判断是过半的
if ((majGroupCounter > (numGroups / 2))) {
LOG.debug("Positive set size: {}", set.size());
return true;
} else {
LOG.debug("Negative set size: {}", set.size());
return false;
}
}已经过半了,但是recvqueue里面的通知还没处理完,还有可能有更适合的Leader通知
- 如果有更合适的,将通知重新加入recvqueue队列的尾部,并break退出循环,此时n != null ,不会进行收尾动作,会重新进行选举,最终还是会更新当前Server的推荐信息为这个更适合的Leader,并广播出去
- 如果没有,即n为null,则说明当前server所推荐的leader就是最终的leader,则此时就可以进行收尾工作了
6.5 无需选举的情况
在代码中已经写的听清楚的,不在赘述。
7. QuorumPeer处理选举结果
在经过前面一系列通信后集群机器终于是选举出了Leader及Follower,在例子中C为Leader,接下来简单的分析下lookForLeader()方法返回后是如何由选举流程进入到数据同步流程的。
代码还是上一篇分析过的QuorumPeer代码,只是现在会以确认了Leader来分析,关键源码如下:
public class QuorumPeer extends ZooKeeperThread
implements QuorumStats.Provider {
// 集群对象会含有三种不同的角色对象,如果机器在选举时被表明了是什么角色时
// 对应的对象将会被初始化,代表着本机器的角色,执行相应的操作
public Follower follower;
public Leader leader;
public Observer observer;
// 代表着本机的当前投票
volatile private Vote currentVote;
@Override
public void run() {
// 源码中这里有个流程是用来注册JMX对象的,这里和选举流程无关因此忽略
try {
// 正式开始ZK集群执行流程,这里会有三种情况:
// 1、如果在选举流程,peerState将一直会是LOOLING,直到集群选举出
// Leader;2、当选出Leader后,本机器的peerState将会变成对应的状态
// 直到Leader宕机不得不选举出新的Leader;3、每一次新的轮询都代表
// 着本机的角色发生了改变,执行的作用也发生改变。
while (running) {
switch (getPeerState()) {
// 代表本机正在进行选举流程
case LOOKING:
// 本机是否开启只读模式,有兴趣的可以去看下,本次只分析
// 普通正常的流程
if (Boolean.getBoolean("readonlymode.enabled")) {
// 忽略
...
} else {
try {
// 选举前先把之前的投票清空,以免对选举流程产生误导
setBCVote(null);
// 在本次投票中,lookForLeader()方法最终返回的
// 投票信息将会是机器C的,因此集群内的每台机器
// currentVote对象保存的都是Leader机器C的信息
setCurrentVote(
makeLEStrategy().lookForLeader());
} catch (Exception e) {
// 如果发生了异常情况则设置本机的状态为选举中
// 以便进入下一次选举流程
setPeerState(ServerState.LOOKING);
}
}
break;
// 代表本机已经确认为Observer角色,正在集群内进行观察
case OBSERVING:
// 选举流程中的Observer不起作用,因此这个流程暂不分析,等到
// 下一篇分析ZK集群的数据同步再来具体分析其作用
break;
// 代表本机已经确认为Follower角色,正在跟随Leader
case FOLLOWING:
try {
// 本机器的上一次轮询确定出了本机器为Follower角色
setFollower(makeFollower(logFactory));
// 开始执行Follower角色的工作:跟随Leader机器
follower.followLeader();
} finally {
// 当本次Follower跟随的集群发生了异常时将会改变本机的
// 角色,重新设置成LOOKING状态选举出新Leader
// 异常情况:1、Leader宕机,导致本集群不得不重新选举;
// 2、本集群内其它的Follower宕机超过半数导致Leader
// 投票数低于总数一半,进行重新选举。
// 如果是本机宕机程序直接死亡,不会进入到Finally块
follower.shutdown();
setFollower(null);
setPeerState(ServerState.LOOKING);
}
break;
// 代表本机已经确认为Leader角色,正在领导集群内的各个机器
case LEADING:
try {
// 本机器的上一次轮询确定出了本机器为Leader角色
setLeader(makeLeader(logFactory));
// 开始执行Leader角色的工作:作为集群中心发送同步命令
leader.lead();
// 退出了lead()方法说明集群的Leader发生了变化,需要
// 选举出新的Leader
setLeader(null);
}finally {
// 关闭当前Leader对象并设置状态LOOKING开始准备下一次
// 选举流程
if (leader != null) {
leader.shutdown("Forcing shutdown");
setLeader(null);
}
setPeerState(ServerState.LOOKING);
}
break;
}
}
} finally {
// 执行到这说明本机器的ZK服务被关闭,将会关闭机器的对象并退出
}
}
}至此选举流程便已经结束,接下来的流程都是在Leader、Follower和Observer具体对象中完成的,即数据同步流程,网上人们习惯称其为广播模式,但我更愿意把这个叫成数据同步流程。因为这个流程实际进行的操作就是同步各个机器间的请求数据,而广播在源码层面看选举流程也进行过广播,因此把这个数据同步流程称为广播模式不太合适。关于数据同步流程将会在下篇文章中进行流程和源码分析,尽情期待。