15. 源码| FLE算法集群选举通信原理及流程结构
上一篇说明了ZK集群的基本结构和重要组件,分析了在ZK集群启动时哪些重要的组件在起作用,这一篇将会续着上一篇往下开始分析ZK集群选举流程,来分析选举细节、选举流程、机器间如何完成交互通信的以及启动流程中的那些组件在其中起到何种作用。简单来说,便是分析上篇文章说的五个要点中的第二个和第三个要点。至于ZK集群的数据同步放到下篇文章再来分析。
注:本篇基于ZK版本3.7 分析的。
1.集群通信结构
集群通信结构图如下:
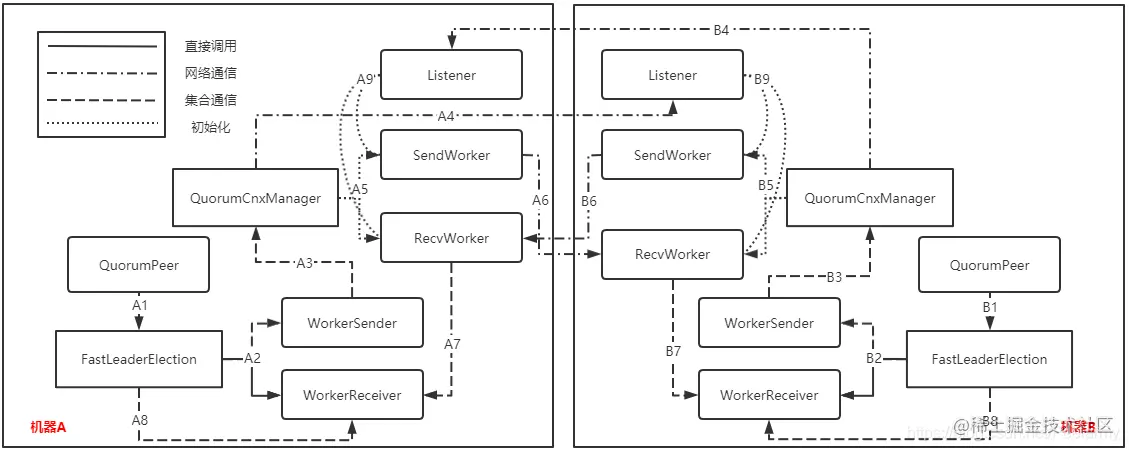
上面的通信图大致描绘了两个机器在启动流程和准备开始选举流程的通信情况,在图中的A1、A2、A3、A4、B1、B2、B3和B4这八个流程在两台机器里1-4流程可以看成是基本同时执行的,并且A1-B1、A2-B2...这八个流程对所处理的操作是一模一样的,只是触发的时间有点差别而已。因此介绍A1流程就相当于介绍B1流程,以此类推,接下来便详细介绍一下其交互顺序和其中的一些细节:
- A2流程:FastLeaderElection想要和其它的机器通信,于是会向本类的sendqueue集合添加消息对象,WorkerSender一直轮询这个集合,轮询到有 消息对象后执行A3流程;
- A3流程:调用QuorumCnxManager对象去发送消息,接着会把消息添加到queueSendMap集合,并判断要发送的机器是否有对应的SendWorker和RecvWorker对去处理这个消息,如果没有则进行A4流程和A5流程;
- A4流程:A4流程在A5流程之前,连接另一台机器Listener对象里面的ServerSocket对象,并触发B9流程,在机器B创建和机器A进行通信的SendWorker和RecvWorker对;
- A5流程:判断本机器是否已经初始化了SendWorker和RecvWorker对来和机器B进行通信,如果没有则创建一个SendWorker和RecvWorker对;
- A6流程:当创建SendWorker成功之后,会轮询queueSendMap集合查看是否有消息需要发送,如果有的话则像机器B的RecvWorker发送消息,从而触发B7流程;
- A7流程:当机器B执行完B6流程时将会触发A7流程,RecvWorker会一直读取通道的数据,如果有数据则会完全读取放入recvQueue集合中,而WorkerReceiver会一直轮询recvQueue集合,当轮询到有响应消息后会把通知对象放入recvqueue集合中,从而触发A8流程;
- A8流程:FastLeaderElection在调完A2流程后会一直等待直到recvqueue有响应数据后才会执行后续的选举流程,但后面的选举流程放到下篇来分析吧;
- A9流程:如果机器B执行了B4流程,相当于机器A执行到了A4流程触发B9一样,Listener将会监听这次连接,进行一定的判断是否要创建SendWorker和RecvWorker对。 看完分析后会发现这几个流程可以一直循环,无穷无尽,当发生了一次新的通信或者选举时将会又一次从A1开启整个流程,执行到最后再次进入选举流程。需要注意的是选举在A1流程便已经开始了
2. 集群通信流程
在介绍集群的通信流程时,假设当前的ZK集群有三台机器,SID分别是1、3、5,分别代表机器A、B和C,启动时间基本一致,接下来便按照这个假设基础往下模拟通信流程吧。
2.1 创建通信模块流程
创建通信流程个人认为应该分两个部分,第一个部分是主动向其它的机器发送Socket连接流程,第二个部分则是接收到其它机器的Socket连接请求所执行的监听流程,只有两个流程都执行完才可以构建前面所说的集群通信结构。
2.1.1 发送Socket连接
每台机器在启动时都会主动向配置文件中的集群发送Socket连接请求和通知,大致图如下:
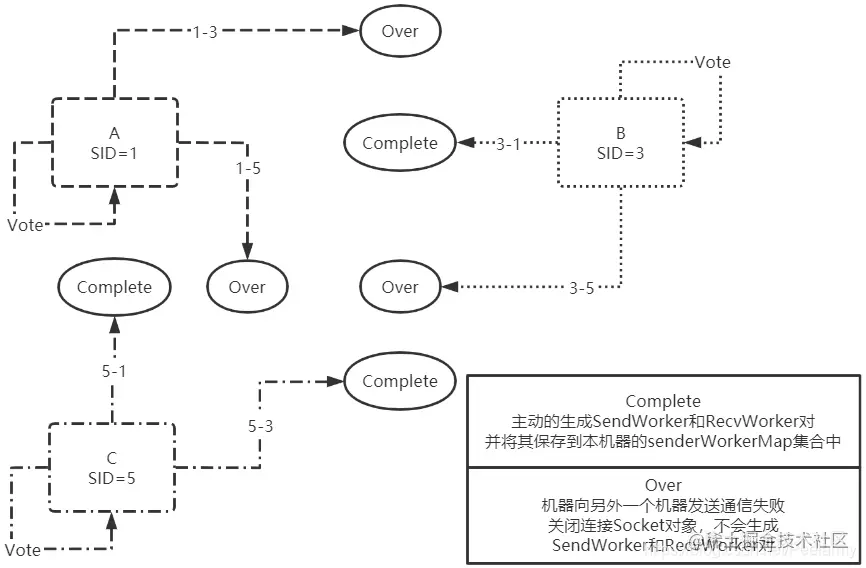
可以看到途中有六个向外的接头,这些箭头代表机器启动时尝试给和其它机器发送Socket连接并发送通知的流程,并且这六个步骤由于启动时间基本一致,所以执行时间也差不多。接下来看下途中的流程结果:
- 1-3流程:机器A向机器B发送Socket请求并尝试发送通知给B,但此时会发送失败;
- 1-5流程:机器A向机器C发送Socket请求并尝试发送通知给C,但发送通知失败;
- 3-1流程:机器B向机器A发送Socket请求并尝试发送通知给A,发送成功;
- 3-5流程:机器B向机器C发送Socket请求并尝试发送通知给C,但发送通知失败;
- 5-1流程:机器C向机器A发送Socket请求并尝试发送通知给A,发送成功;
- 5-3流程:机器C向机器B发送Socket请求并尝试发送通知给B,发送成功;
- 三个Vote流程:每台机器都会向自己发送一条通知,告诉本机选举对象先给自己投一票。
结果分析:仔细看途中的流程会发现一个有趣的现象,SID大的发给小的都成功了,SID小的发给大的都失败了,这是因为在发送完Socket连接后会尝试给连接机器发送一个通知,但在发送前判断发送机器的SID是否比本机器大,如果大的话则不发送请求,直接关闭Socket,如果本机器的SID比另外一台大的话则继续发送把投票投给本机器的通知。
总结:启动时的发送Socket连接流程SID大的将会给SID小于或等于本机器SID的发送Socket连接并发送我把票投给自己的通知,SID小的只会和SID大的连接一下随后关闭Socket连接;
经过这个流程后,SID大的机器将会主动创建和SID小的通信SendWorker和RecvWorker对。结果图如下:
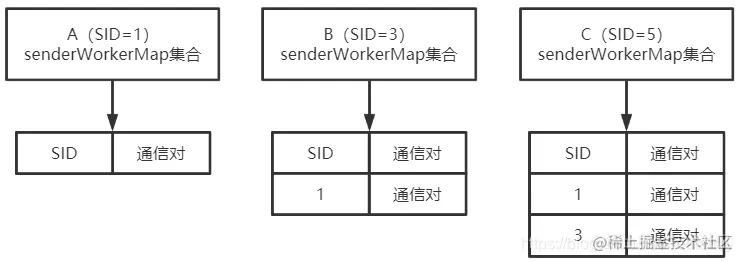
SID最小的A机器senderWorkerMap为空,B机器的senderWorkerMap只有A的通信对,而C机器的senderWorkerMap有A和B的通信对。
2.1.2 接收监听Socket连接
在上一章中提到了每台机器会创建一个Listener用来监听其它机器的Socket连接本机器情况,在发送Socket连接流程中提到了每个机器都会向其它的机器发送Socket连接,有Socket连接时都会触发本机的ServerSocket服务监听。监听结果图如下:
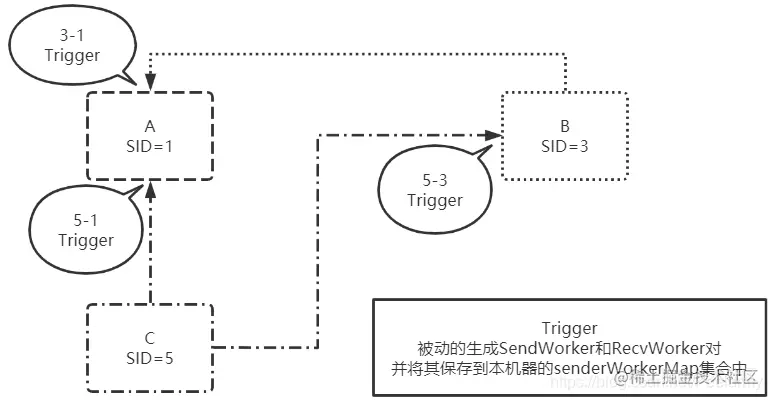
上图中只有三个成功触发流程,但在刚刚的发送Socket流程中明明有六个Socket发送,应该有六个成功触发流程才对呀,这是咋回事呢?不急,先看下图中触发结果:
- 3-1流程:机器B发送给机器A的Socket通信成功触发;
- 5-1流程:机器C发送给机器A的Socket通信成功触发;
- 5-3流程:机器C发送给机器B的Socket通信成功触发;
- 其余的1-3、1-5和3-5流程发送Socket通信监听流程属于连接重置流程了,稍后分析。
结果分析:从结果来看SID大的发送完Socket连接请求后将会在SID小的机器上触发监听并生成SendWorker和RecvWorker通信对,如果SID小的机器上原来就有发送Socket连接的通信对则会覆盖。
总结:无论是主动的创建SendWorker和RecvWorker通信对还是监听式的创建,主动权永远在都在SID大的机器上,SID大的机器主动发送通知创建通信对,而SID小的又因为SID大的机器主动发送Socket连接而导致被动的创建通信对。
经过上两个流程后,各个机器中的senderWorkerMap状况:
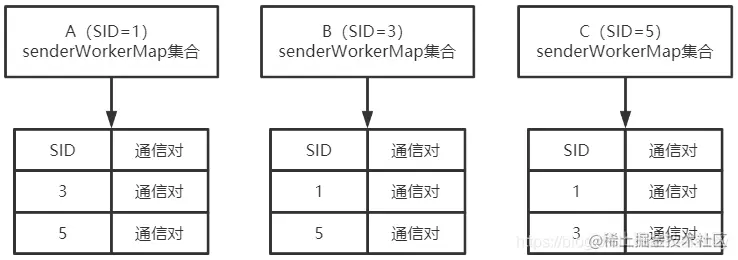
经过主动和被动的创建通信对,集群中的每个机器都会有另外机器的通信对,以保持进行选举时的投票通知。
2.1.3 Socket连接重置
此次我们模拟的选举通信的例子是三台机器几乎同时启动,因此向另外的机器发送Socket连接等操作都可以看成是同时操作的,操作完之后便形成了每个机器中都含有另外一些机器的通信对。但是加入在运行过程中机器A宕机重启了或者机器SID大的先启动,随后SID小的再启动,此时有一方都没启动,按照刚刚的两个流程来走肯定是走不通的。
因此便有了Socket连接重置操作,这样可以确保后面启动的机器也可以和先启动的机器成功创建通信对。假设机器A和C已经启动成功了,但是还在选举通信的创建通信对过程,此时大致流程图如下:
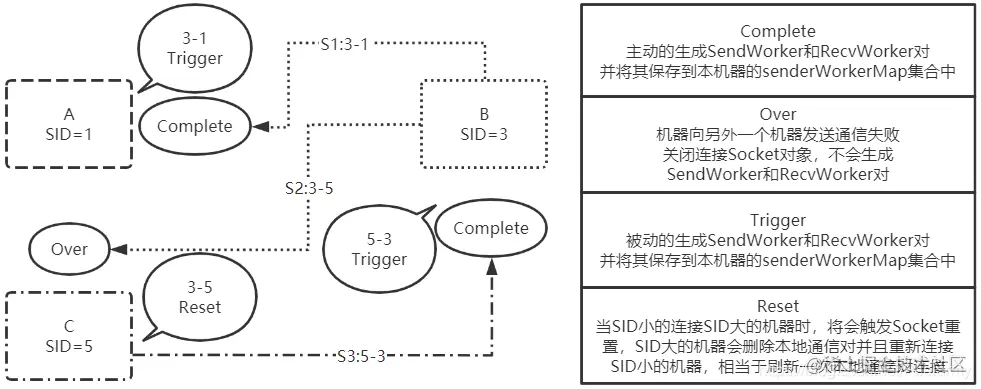
在前面出现过的Complete、Over和Trigger之外又多了Reset事件,在这里面代表了Socket连接重置事件,这张图是更接近于平时正常使用ZK集群的流程,因为正常启动流程下几台机器的启动时间基本上是异步的。接下来详细分析一下图中流程:
- S1:3-1流程:假设B机器首先向SID小的A机器发送了连接Socket请求,此时会在B机器上生成和A机器通信的通信对,而A机器因为B机器Socket连接进来且B机器的SID大于A机器的SID,因此会触发处理事件,从而在A机器上生成和B机器通信的通信对;
- S2:3-5流程:B机器向A机器发送Socket连接请求,但由于C机器的SID比B机器的SID要大,因此B机器会发送通知失败,但C机器依然可以接收到Socket请求,且在C机器上会触发重置Socket连接的操作,将本地和机器B通信的通信对(如果以前有的话)关闭,并重新连接B机器,创建和B机器通信的通信对;
- S3:5-3流程:当S2的重置事件触发后C机器会向B机器发送连接Socket请求,满足了SID大的机器连接SID小的机器情景,因此会在B机器上触发事件,生成和C机器通信的通信对。
结果分析:当SID小的机器B向SID大的机器C发送连接Socket请求时,将会在C机器上触发重置事件,将本机器和B通信的通信对重置并重新发送连接Socket请求,从而满足SID大的机器向SID小的机器发送Socket请求,在B机器上创建通信的通信对。
结论:经过上述流程后可以发现重置操作类似于SID小的机器要求SID大的机器再次主动联系本机器,从而满足SID大的机器主动发送Socket连接情景,在两台机器上彼此创建通信的通信对,可以把重置操作看成主动通信和被动触发的转换操作,将主动发送的转变成被动接收的,将被动接收的转变成主动发送的。
2.2 选举通信流程
2.2.1 选举规则
前面建立通信对流程是选举通信流程的必备前提,完成了前面通信对的建立便可以开始进行选举投票交换了。FLE选举的规则如下,且优先级从上到下排列:
Epoch谁大谁当选:Epoch类似于古代的朝代,每更替一个朝代Epoch就会+1,正常的ZK集群机器运行时所有的机器Epoch都是一样的,说明在同一个选举结果中。当某个机器收到Epoch要大的说明因为某种意外新的选举结果未收到,因此收到新的朝代信息直接变成Follower加入;zxid谁大谁当选:在ZK集群中zxid是全局唯一的,处理请求时都是往上递增的,因此选举时谁的zxid要大说明谁接收的信息最多,应该成为Leader以便最大限度的减少请求的丢失;myid谁大谁当选:在初始阶段Epoch和zxid都是一样的,因此需要有一个最基本的值来衡量谁来当Leader,这个最基本的值便是每台机器都拥有的myid。
2.2.2 涉及参数
选举流程会涉及如下几个参数交换:
proposedLeader:当前机器选举Leader的myid,最开始每台机器都会把这个值设置为自己的myid;proposedZxid:当前机器选举Leader的zxid,这里面包含了本机的epoch信息,最开始的值为自己机器的zxid;proposedEpoch:当前机器的迭代数(朝代数),最开始为本机器初始化的迭代数,但在进行选举时发送给其它机器值为logicalclock逻辑迭代数;electionEpoch:接收通知时使用的参数,对应于发送通知机器的logicalclock值;peerEpoch:接收通知时使用的参数,对应于发送通知机器的proposedEpoch迭代数。
2.2.3 选举流程
大致选举通信流程如下图:
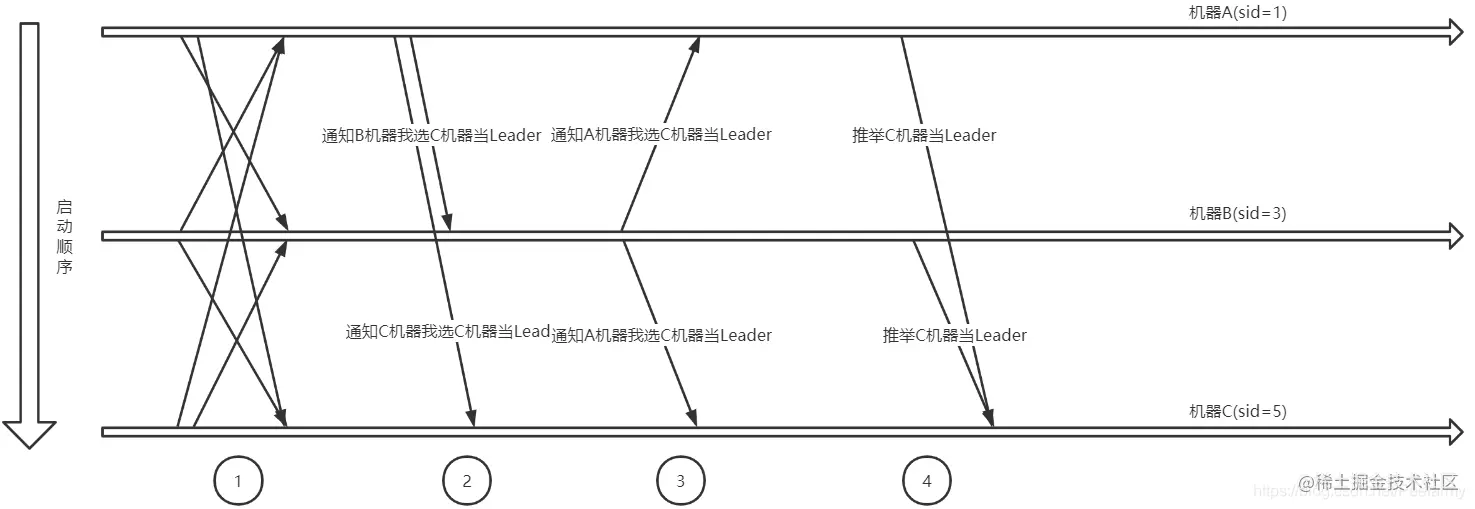
流程分析如下:
- 成功建立通信对后将会从queueSendMap集合中取出通知发送给集群中的每个机器告诉它们选举自己当选Leader,并把自己的proposedLeader、proposedZxid和proposedEpoch等值信息放到通知中,以便其它机器收到后作比对。如机器A最开始就会向B和C机器发送选举自己当Leader的通知,B和C机器也会这样做;
- 先从机器A分析起,在这个步骤下,机器A、B和C都接收到了其它机器的选举通知,并使用前面所说的选举规则进行过判断。假设A先收到B的通知,先把选举投给了B,但是后面又收到了C的通知,最后把投票改投给了C,如果是先收到C的通知,那么B的通知将会被忽略,最终都会把票投给C机器;
- B机器会收到A和C的通知,但是A的通知会被忽略,因为根据FLE算法的规则A的权重比B的小,但是C的权重比B要大,因此B最终会把投票投给机器C;
- 此时集群内的三台机器已经收到了全部通知并把票已经给投了,最终算上C自己的投票,C的投票是肯定超过总数的半数的。于是C将自己的状态改成Leader,而A和B则把自己的状态改成Follower,修改的依据便是判断超过半数的机器信息myid是否和本机器相同,相同则是Leader,否则是Follower。
3. 重要类、成员变量的解读
3.1 QuorumPeer
一个QuorumPeer可以理解为一个准备参加选举的ZK的server,即配置文件zoo.cfg中配置的服务器 代表具有选举权的Server,它具有三个状态LOOKING, FOLLOWING, LEADING(不包含OBSERVING状态)
/**
* This class manages the quorum protocol. There are three states this server can be in:
* <ol>
* <li>Leader election - each server will elect a leader (proposing itself as a
* leader initially).</li>
* <li>Follower - the server will synchronize with the leader and replicate any
* transactions.</li>
* <li>Leader - the server will process requests and forward them to followers.
* A majority of followers must log the request before
* it can be accepted.</li>
* </ol>
* 翻译:这个类管理着“法定人数投票”协议。这个服务器有三个状态:
* (1)Leader election:(处于该状态的)每一个服务器将选举一个Leader(最初推荐自
* 己作为Leader)。(这个状态即LOOKING状态)
* (2)Follower:(处于该状态的)服务器将与Leader做同步,并复制所有的事务(注意这里的事务指
* 的是最终的提议Proposal。不要忘记txid中的tx即为事务)。
* (3)Leader:(处于该状态的)服务器将处理请求,并将这些请求转发给其它Follower。
* 大多数Follower在该写请求被批准之前(before it can be accepted)都必须
* 要记录下该请求(注意,这里的请求指的是写请求,Leader在接收到写请求后会向所有
* Follower发出提议,在大多数Follower同意后该写请求才会被批准)。
*
* This class will setup a datagram socket that will always respond with its
* view of the current leader. The response will take the form of:
* 翻译:这个类将设置一个数据报套接字(就是一种数据结构),这个数据报套接字将
* 总是使用它的视图(格式)来响应当前的Leader。响应将采用的格式为:
*
* <pre>
* int xid;
*
* long myid;
*
* long leader_id;
*
* long leader_zxid;
* </pre>
*
* The request for the current leader will consist solely
* of an xid: int xid;
* 翻译:当前Leader的请求将仅(solely)包含(consist)一个xid(注意,xid即事务id,
* 是一个新的提议的唯一标识)。
*
*/
public class QuorumPeer extends ZooKeeperThread implements QuorumStats.Provider {
...
}3.2 FastLeaderElection 选举类
系统初始化时,每一个QuorumPeer对象维护了一个FastLeaderElection对象来为自己的选举工作进行代言。
/**
* Implementation of leader election using TCP. It uses an object of the class
* QuorumCnxManager to manage connections. Otherwise, the algorithm is push-based
* as with the other UDP implementations.
* 翻译:使用TCP实现了Leader的选举。它使用QuorumCnxManager类的对象进行连接管理
* (与其它Server间的连接管理)。否则(即若不使用QuorumCnxManager对象的话),将使用
* UDP的基于推送的算法实现。
*
* There are a few parameters that can be tuned to change its behavior. First,
* finalizeWait determines the amount of time to wait until deciding upon a leader.
* This is part of the leader election algorithm.
* 翻译:有几个参数可以用来改变它(选举)的行为。第一,finalizeWait(这是一个代码中的常量)
* 决定了选举出一个Leader的时间,这是Leader选举算法的一部分。
*/
public class FastLeaderElection implements Election {
private static final Logger LOG = LoggerFactory.getLogger(FastLeaderElection.class);
/**
* 翻译:完成等待时间,一旦它(这个过程)认为它已经到达了选举的最后。
* (该常量)确定还需要等待多长时间
*
* 解释:
* finalizeWait:选举时发送投票给其他服务器,并接受回复,接受到所有回复用到到最长时间就是200毫秒
* 因为一般200毫秒之内选举已经结束了,所以一般都低于200毫秒
*/
final static int finalizeWait = 200;
/**
* 翻译:(该常量指定了)两个连续的notification检查间的时间间隔上限。
* 它影响了系统在经历了长时间分割后再次重启的时间。目前60秒。
*
* 该常量是前面的finalizeWait所描述的超时时限的最大值
*
* 解释:
* finalizeWait这个值会增大,直到增大到maxNotificationInterval,一但到达maxNotificationInterval,
* 还没有选举出来(长时间分割意思就是没有leader),就会重启机器,相当于重新再进行一次新的选举
*/
final static int maxNotificationInterval = 60000;
/**
* 翻译:连接管理者。FastLeaderElection(选举算法)使用TCP(管理)
* 两个同辈Server的通信,并且QuorumCnxManager还管理着这些连接。
*
* 解释:通过该类管理和其他Server之间的TCP连接
*/
QuorumCnxManager manager;
// 可以简单理解为:代表当前参与选举的Server
QuorumPeer self;
// 逻辑时钟
AtomicLong logicalclock = new AtomicLong(); /* Election instance */
// 记录当前Server所推荐的leader信息,即ServerId,Zxid,Epoch
long proposedLeader;
long proposedZxid;
long proposedEpoch;
/**
* 翻译:Notifications是一个让其它Server知道当前Server已经改变
* 了投票的通知消息,(为什么它要改变投票呢?)要么是因为它参与了
* Leader选举(新一轮的投票,首先投向自己),要么是它知道了另一个
* Server具有更大的zxid,或者zxid相同但ServerId更大(所以它要
* 通知给其它所有Server,它要修改自己的选票)。
*/
static public class Notification {
...
/*
* 它是一个内部类,里面封装了:
* leader:proposed leader,当前通知所推荐的leader的serverId
* zxid:当前通知所推荐的leader的zxid
* electionEpoch:当前通知所处的选举epoch,即逻辑时钟
* state:QuorumPeer.ServerState,当前通知发送者的状态
* 四个状态:LOOKING, FOLLOWING, LEADING, OBSERVING;
* sid:当前发送者的ServerId
* peerEpoch: 当前通知所推荐的leader的epoch
*/
long leader;
long zxid;
long electionEpoch;
QuorumPeer.ServerState state;
long sid;
long peerEpoch;
...
}
/**
* Notification是作为本地处理通知消息时封装的对象
* 如果要将通知发送出去或者接收,用的是ToSend对象,其成员变量和Notification一致
*/
static public class ToSend {
static enum mType {crequest, challenge, notification, ack}
ToSend(mType type,
long leader,
long zxid,
long electionEpoch,
ServerState state,
long sid,
long peerEpoch) {
...
}
...
}
/**
* 发送投票通知的时候,将ToSend封装的选票信息转换成二进制字节数据传输
*/
static ByteBuffer buildMsg(int state,
long leader,
long zxid,
long electionEpoch,
long epoch) {
byte requestBytes[] = new byte[40];
ByteBuffer requestBuffer = ByteBuffer.wrap(requestBytes);
/*
* Building notification packet to send
* 注意,是按照一定顺序转换的,接收的时候也按照该顺序解析
*/
requestBuffer.clear();
requestBuffer.putInt(state);
requestBuffer.putLong(leader);
requestBuffer.putLong(zxid);
requestBuffer.putLong(electionEpoch);
requestBuffer.putLong(epoch);
requestBuffer.putInt(Notification.CURRENTVERSION);
return requestBuffer;
}
/**
* 选举时发送和接收选票通知都是异步的,先放入队列,有专门线程处理
* 下面两个就是发送消息队列,和接收消息的队列
*/
LinkedBlockingQueue<ToSend> sendqueue;
LinkedBlockingQueue<Notification> recvqueue;
Messenger messenger;
/**
* 翻译:消息处理程序的多线程实现。Messenger实现了两个子类:WorkReceiver和WorkSender。
* 从名称可以明显看出它们的功能。每一个都生成一个新线程。
*
* 解释:通过创建该类可以创建两个线程分别处理消息发送和接收
*/
protected class Messenger {
/**
* 翻译:接收QuorumCnxManager实例在方法run()上的消息,并处理这些消息。
*/
class WorkerReceiver extends ZooKeeperThread {
//大概逻辑就是通过QuorumCnxManager manager,获取其他Server发来的消息,然后处理,如果
//符合一定条件,放到recvqueue队列里
...
}
/**
* 翻译:这个worker只是取出要发送的消息并将其放入管理器的队列中。
*/
class WorkerSender extends ZooKeeperThread {
//大概逻辑就是从sendqueue队列中获取要发送的消息ToSend对象,调用上面说过的buildMsg方法
//转换成字节数据,再通过QuorumCnxManager manager广播出去
...
}
WorkerSender ws;
WorkerReceiver wr;
/**
* Constructor of class Messenger.
* 通过构造Messenger对象,即可启动两个线程处理收发消息
*/
Messenger(QuorumCnxManager manager) {
this.ws = new WorkerSender(manager);
Thread t = new Thread(this.ws,"WorkerSender[myid=" + self.getId() + "]");
t.setDaemon(true);
t.start();
this.wr = new WorkerReceiver(manager);
t = new Thread(this.wr,"WorkerReceiver[myid=" + self.getId() + "]");
t.setDaemon(true);
t.start();
}
/**
* Stops instances of WorkerSender and WorkerReceiver
* 调用该方法,让收发消息两个线程停止工作
*/
void halt(){
this.ws.stop = true;
this.wr.stop = true;
}
}
...
/**
* 翻译:FastLeaderElection的构造函数。它接受两个参数,
* 一个是实例化此对象的QuorumPeer对象,另一个是连接管理器。
* 在ZooKeeper服务的一个实例期间,每个对等点只应该创建这样的对象一次。
*/
public FastLeaderElection(QuorumPeer self, QuorumCnxManager manager){
this.stop = false;
this.manager = manager;
//starter:启动选举,初始化一些数据、启动收发消息的线程等操作..
starter(self, manager);
}
...
/**
* 翻译:开启新一轮的Leader选举。无论何时,只要我们的QuorumPeer的
* 状态变为了LOOKING,那么这个方法将被调用,并且它会发送notifications
* 给所有其它的同级服务器。
*
* 这个方法就是选举的核心方法!!!!!!!!后面专门讲解这个方法
*/
public Vote lookForLeader() throws InterruptedException {
}
...
}3.3 QuorumCnxManager 连接管理器
QuorumCnxManager 这个类我们只需要知道该类大概的作用就可以了。
/**
* This class implements a connection manager for leader election using TCP. It
* maintains one connection for every pair of servers.
* The tricky part is to guarantee that there is exactly
* one connection for every pair of servers that are operating correctly
* and that can communicate over the network.
* 翻译:这个类为使用TCP的领袖选举实现了一个连接管理器。
* 它为每对服务器维护一个连接。棘手的部分是确保每一对服务器都有一个连接,
* 这些服务器都在正确地运行,并且可以通过网络进行通信。
*
* 解释:每队服务器维护一个连接的意思就是A连接服务器
*
* If two servers try to start a connection concurrently, then the
* connection manager uses a very simple tie-breaking mechanism
* to decide which connection to drop based on the IP addressed of
* the two parties.
* 翻译:如果两个服务器试图同时启动一个连接,则连接管理器使用非常简单的中断连接
* 机制来决定哪个中断,基于双方的IP地址。
*
* For every peer, the manager maintains a queue of messages to send. If the
* connection to any particular peer drops, then the sender thread
* puts the message back on the list. As this implementation
* currently uses a queue implementation to maintain messages to send to
* another peer, we add the message to the tail of the queue, thus
* changing the order of messages.Although this is not a problem for the
* leader election, it could be a problem when consolidating peer
* communication. This is to be verified, though.
* 翻译:对于每个对等体,管理器维护着一个消息发送队列。如果连接到任何
* 特定的Server中断,那么发送者线程将消息放回到这个队列中。
* 作为这个实现,当前使用一个队列来实现维护发送给另一方的消息,因此我们将消息
* 添加到队列的尾部,从而更改了消息的顺序。虽然对于Leader选举来说这不是一个问题,
* 但对于加强对等通信可能就是个问题。不过,这一点有待验证。
*
* 解释:比如发送消息1给某一个Server,如果和该Server连接断开后,想再给该Server发送消息2时
* 此时消息就会存到该Server在本地对应维护的一个消息发送队列中,等连接恢复后会重新尝试发送。
*/
public class QuorumCnxManager {
...
//每一个QuorumPeer都有一个QuorumCnxManager对象负责选举期间QuorumPeer之间连接的
//建立和发送、接收消息队列的维护,而这些消息是通过以下4个集合被处理的:
//发送器集合。每个SenderWorker消息发送器,都对应一台远程ZooKeeper服务器,负责消息的发送,在这个集合中,key为SID
final ConcurrentHashMap<Long, SendWorker> senderWorkerMap;
//每个SID需要发送的消息队列
final ConcurrentHashMap<Long, ArrayBlockingQueue<ByteBuffer>> queueSendMap;
最近发送过的消息。在这个集合中,为每个SID保留最近发送过的一个消息
final ConcurrentHashMap<Long, ByteBuffer> lastMessageSent;
//收到的消息存放到该队列
public final ArrayBlockingQueue<Message> recvQueue;
...
}这个类维护了当前Server和其他Server之间的TCP连接,并且保证了服务器之间只有一个连接。 另外该类还维护了一个Map结构的数据queueSendMap,其中key为集群中其他Server的ServerId,value为一个消息队列,保存了当前Server给其他Server发送消息时失败的消息副本。 有一个点需要关注,通过本地维护的消息队列,可以判断当前Server与集群之间的连接是否正常,如下图:

QuorumCnxManager还有分别负责消息的发送和接收的SenderWorker和RecvWorker两个继承了Runnable接口的线程内部类,这两个线程类的构造方法如下:
SendWorker(Socket sock, Long sid) {
super("SendWorker:" + sid);
this.sid = sid;
this.sock = sock;
recvWorker = null;
try {
dout = new DataOutputStream(sock.getOutputStream());
} catch (IOException e) {
LOG.error("Unable to access socket output stream", e);
closeSocket(sock);
running = false;
}
LOG.debug("Address of remote peer: " + this.sid);
}
RecvWorker(Socket sock, Long sid, SendWorker sw) {
super("RecvWorker:" + sid);
this.sid = sid;
this.sock = sock;
this.sw = sw;
try {
din = new DataInputStream(sock.getInputStream());
// OK to wait until socket disconnects while reading.
sock.setSoTimeout(0);
} catch (IOException e) {
LOG.error("Error while accessing socket for " + sid, e);
closeSocket(sock);
running = false;
}
}每个SenderWorker或者RecvWorker都有一个sid变量,显然,每一个sid对应的QuorumPeer都会有与之对应的SenderWorker和RecvWorker来专门负责处理接收到的它的消息或者向它发送消息。
接下来再看下对应的run()方法做了什么操作 SendWorker.run():
pubic void run() {
threadCnt.incrementAndGet();
try {
/**
* If there is nothing in the queue to send, then we
* send the lastMessage to ensure that the last message
* was received by the peer. The message could be dropped
* in case self or the peer shutdown their connection
* (and exit the thread) prior to reading/processing
* the last message. Duplicate messages are handled correctly
* by the peer.
*
* If the send queue is non-empty, then we have a recent
* message than that stored in lastMessage. To avoid sending
* stale message, we should send the message in the send queue.
*/
ArrayBlockingQueue<ByteBuffer> bq = queueSendMap.get(sid);
if (bq == null || isSendQueueEmpty(bq)) {
ByteBuffer b = lastMessageSent.get(sid);
if (b != null) {
LOG.debug("Attempting to send lastMessage to sid=" + sid);
send(b);
}
}
} catch (IOException e) {
LOG.error("Failed to send last message. Shutting down thread.", e);
this.finish();
}
try {
while (running && !shutdown && sock != null) {
ByteBuffer b = null;
try {
ArrayBlockingQueue<ByteBuffer> bq = queueSendMap
.get(sid);
if (bq != null) {
b = pollSendQueue(bq, 1000, TimeUnit.MILLISECONDS);
} else {
LOG.error("No queue of incoming messages for " +
"server " + sid);
break;
}
if(b != null){
lastMessageSent.put(sid, b);
send(b);
}
} catch (InterruptedException e) {
LOG.warn("Interrupted while waiting for message on queue",
e);
}
}
} catch (Exception e) {
LOG.warn("Exception when using channel: for id " + sid + " my id = " +
self.getId() + " error = " + e);
}
this.finish();
LOG.warn("Send worker leaving thread");
}
}RecvWorker.run():
public void run() {
threadCnt.incrementAndGet();
try {
while (running && !shutdown && sock != null) {
/**
* Reads the first int to determine the length of the
* message
*/
int length = din.readInt();
if (length <= 0 || length > PACKETMAXSIZE) {
throw new IOException(
"Received packet with invalid packet: "
+ length);
}
/**
* Allocates a new ByteBuffer to receive the message
*/
byte[] msgArray = new byte[length];
din.readFully(msgArray, 0, length);
ByteBuffer message = ByteBuffer.wrap(msgArray);
addToRecvQueue(new Message(message.duplicate(), sid));
}
} catch (Exception e) {
LOG.warn("Connection broken for id " + sid + ", my id = " +
self.getId() + ", error = " , e);
} finally {
LOG.warn("Interrupting SendWorker");
sw.finish();
if (sock != null) {
closeSocket(sock);
}
}
}代码可以看到,SenderWorker负责不断从全局的queueSendMap中读取自己所负责的sid对应的消息的列表,然后将消息发送给对应的sid。
而RecvWorker负责从与自己负责的sid建立的TCP连接中读取数据放入到recvQueue的末尾。
从QuorumCnxManager.SenderWorker和QuorumCnxManager.RecvWorker的run方法中可以看出,这两个worker都是基于QuorumCnxManager建立的连接,与对应的server进行消息的发送和接收,而要发送的消息则来自FastLeaderElection,接收到的消息,也是被FastLeaderElection处理,因此,QuorumCnxManager的两个worker并不负责具体的算法实现,只是消息发送、接收的代理类,FastLeaderElection不需要理睬怎么与其它的server通信、怎么获得其它server的投票信息这些细节,只需要从QuorumCnxManager提供的队列里面取消息或者放入消息。
FastLeaderElection.Messenger.WorkerReceiver 和 FastLeaderElection.Messenger.WorkerSender
在选举过程中需要进行消息的沟通,因此在FastLeaderElection中维护了两个变量:
LinkedBlockingQueue<ToSend> sendqueue;
LinkedBlockingQueue<Notification> recvqueue;recvqueue中存放了选举过程中接收到的消息,这些消息被交给了FastLeaderElection的最核心方法lookForLeader()进行处理以选举出leader。而sendqueue中存放了待发送出去的消息。
同时,每一个FastLeaderElection变量维护了一个内置类Messager,Messager类包含了两个实现了Runnable接口的类WorkerReceiver和WorkerSender,从名字可以看出,这两个类分别负责消息的发送和接收。即WorkerReceiver负责接收消息并将接收到的消息放入recvqueue中等待处理,WorkerSender负责从sendqueue中取出待发送消息,交给下层的连接管理类QuorumCnxManager进行发送。
下面,我们来看看FastLeaderElection.Messager.WorkekSender和 FastLeaderElection.Messager.WorkerReceiver各自的run方法:
WorkerSender.run():很简单不说了。
public void run() {
while (!stop) {
try {
ToSend m = sendqueue.poll(3000, TimeUnit.MILLISECONDS);
if(m == null) continue;
process(m);
} catch (InterruptedException e) {
break;
}
}
LOG.info("WorkerSender is down");
}
/**
* Called by run() once there is a new message to send.
*
* @param m message to send
*/
void process(ToSend m) {
ByteBuffer requestBuffer = buildMsg(m.state.ordinal(),
m.leader,
m.zxid,
m.electionEpoch,
m.peerEpoch);
manager.toSend(m.sid, requestBuffer);
}WorkerReceiver.run():
public void run() {
Message response;
while (!stop) {
// Sleeps on receive
try{
response = manager.pollRecvQueue(3000, TimeUnit.MILLISECONDS);
if(response == null) continue;
/*
* 翻译:如果它是来自一个观察者,立即响应。注意,下面的谓词假设,
* 如果服务器不是追随者,那么它必须是观察者。如果将来我们遇到其
* 他类型的学习者,我们就必须改变我们检查观察者的方式。
*
* 即:如果收到的选票是来自观察者的,直接返回当前的Server的当前选票
*/
if(!validVoter(response.sid)){
Vote current = self.getCurrentVote();
ToSend notmsg = new ToSend(ToSend.mType.notification,
current.getId(),
current.getZxid(),
logicalclock.get(),
self.getPeerState(),
response.sid,
current.getPeerEpoch());
sendqueue.offer(notmsg);
} else {
// Receive new message
if (LOG.isDebugEnabled()) {
LOG.debug("Receive new notification message. My id = "
+ self.getId());
}
/*
* We check for 28 bytes for backward compatibility
*/
if (response.buffer.capacity() < 28) {
LOG.error("Got a short response: "
+ response.buffer.capacity());
continue;
}
boolean backCompatibility = (response.buffer.capacity() == 28);
response.buffer.clear();
// Instantiate Notification and set its attributes
// 将收到的通知解析后会封装成Notification 放入队列recvqueue
Notification n = new Notification();
// State of peer that sent this message
QuorumPeer.ServerState ackstate = QuorumPeer.ServerState.LOOKING;
// 判断该通知的发送者的状态
switch (response.buffer.getInt()) {
case 0:
ackstate = QuorumPeer.ServerState.LOOKING;
break;
case 1:
ackstate = QuorumPeer.ServerState.FOLLOWING;
break;
case 2:
ackstate = QuorumPeer.ServerState.LEADING;
break;
case 3:
ackstate = QuorumPeer.ServerState.OBSERVING;
break;
default:
continue;
}
n.leader = response.buffer.getLong();
n.zxid = response.buffer.getLong();
n.electionEpoch = response.buffer.getLong();
n.state = ackstate;
n.sid = response.sid;
if(!backCompatibility){
n.peerEpoch = response.buffer.getLong();
} else {
if(LOG.isInfoEnabled()){
LOG.info("Backward compatibility mode, server id=" + n.sid);
}
n.peerEpoch = ZxidUtils.getEpochFromZxid(n.zxid);
}
/*
* Version added in 3.4.6
*/
n.version = (response.buffer.remaining() >= 4) ?
response.buffer.getInt() : 0x0;
/*
* Print notification info
*/
if(LOG.isInfoEnabled()){
printNotification(n);
}
if(self.getPeerState() == QuorumPeer.ServerState.LOOKING){
//如果当前Server状态是Looking,则将该选票放入recvqueue队列,用来参与选举
recvqueue.offer(n);
//如果发送该选票的Server状态也是Looking,并且它的选举逻辑时钟比我小,则发送我当前的选票给他
if((ackstate == QuorumPeer.ServerState.LOOKING)
&& (n.electionEpoch < logicalclock.get())){
Vote v = getVote();
ToSend notmsg = new ToSend(ToSend.mType.notification,
v.getId(),
v.getZxid(),
logicalclock.get(),
self.getPeerState(),
response.sid,
v.getPeerEpoch());
sendqueue.offer(notmsg);
}
} else {
// 如果当前服务器不是LOOKING,即已经选出Leader了,并且该消息的发送者是Looking
// 则我会将当前选票发给他
Vote current = self.getCurrentVote();
if(ackstate == QuorumPeer.ServerState.LOOKING){
if(LOG.isDebugEnabled()){
LOG.debug("Sending new notification. My id = " +
self.getId() + " recipient=" +
response.sid + " zxid=0x" +
Long.toHexString(current.getZxid()) +
" leader=" + current.getId());
}
ToSend notmsg;
if(n.version > 0x0) {
notmsg = new ToSend(
ToSend.mType.notification,
current.getId(),
current.getZxid(),
current.getElectionEpoch(),
self.getPeerState(),
response.sid,
current.getPeerEpoch());
} else {
Vote bcVote = self.getBCVote();
notmsg = new ToSend(
ToSend.mType.notification,
bcVote.getId(),
bcVote.getZxid(),
bcVote.getElectionEpoch(),
self.getPeerState(),
response.sid,
bcVote.getPeerEpoch());
}
sendqueue.offer(notmsg);
}
}
}
} catch (InterruptedException e) {
System.out.println("Interrupted Exception while waiting for new message" +
e.toString());
}
}
LOG.info("WorkerReceiver is down");
}3.4 QuorumVerifier
zk从3.5以后版本就可以实现动态扩缩容,QuorumVerifier其实对应的是一个版本的zoo.cfg.dynamic的动态配置。
/**
* All quorum validators have to implement a method called
* containsQuorum, which verifies if a HashSet of server
* identifiers constitutes a quorum.
*
* 所有quorum验证器都必须实现一个名为containsQuorum的方法,
* 该方法验证ServerId的HashSet是否构成大多数
*/
// QuorumVerifier其实对应的是一个版本的zoo.cfg.dynamic的动态配置
public interface QuorumVerifier {
// 获取指定server的weight权重
// 性能越好的server一般要设置越大的权重
long getWeight(long id);
// 用于判断给定的set集合中包含的serverId是否已经达到了过半(大多数)
boolean containsQuorum(Set<Long> set);
// 其对应的就是zoo.cfg.dynamic的版本
long getVersion();
void setVersion(long ver);
// 获取动态配置文件中不同类型的server集合
Map<Long, QuorumServer> getAllMembers();
Map<Long, QuorumServer> getVotingMembers();
Map<Long, QuorumServer> getObservingMembers();
boolean equals(Object o);
/*
* Only QuorumOracleMaj will implement these methods. Other class will raise warning if the methods are called and
* return false always.
* */
default boolean updateNeedOracle(List<LearnerHandler> forwardingFollowers) {
return false;
}
default boolean getNeedOracle() {
return false;
}
default boolean askOracle() {
return false;
}
default boolean overrideQuorumDecision(List<LearnerHandler> forwardingFollowers) {
return false;
}
default boolean revalidateOutstandingProp(Leader self, ArrayList<Leader.Proposal> outstandingProposal, long lastCommitted) {
return false;
}
default boolean revalidateVoteset(SyncedLearnerTracker voteSet, boolean timeout) {
return false;
}
default String getOraclePath() {
return null;
};
String toString();
}其主要实现类QuorumHierarchical如下:
/*
*
* 这个类实现了一个层次量化的验证器。通过这种结构,zookeeper服务器被分成不相交的组,并且
* * 每个服务器都有一个权重。对于大多数group,如果我们获得的权重超过这个group总权重的一半,
* * 我们就获得大多数(过半)。
*
* quorums的配置使用两个参数:组和权重。组是ZooKeeper服务器的集合,
* * 我们设置一个组,通过传递一个以冒号分隔的server id列表。它还需要为server分配权重。
* * 以下是一个配置示例,该配置创建三个group并为每个server分配权重为1:
*
* group.1=1:2:3
* group.2=4:5:6
* group.3=7:8:9
*
* weight.1=1
* weight.2=1
* weight.3=1
* weight.4=1
* weight.5=1
* weight.6=1
* weight.7=1
* weight.8=1
* weight.9=1
*
* 注意,默认情况下,每个server就是一个group,groupId就是severId;
* 每个participant的weight默认为1,每个observer的weight默认为0
* Note that it is still necessary to define peers using the server keyword.
*
* 请注意,仍然需要使用server关键字定义对等点。
* server.1=...
* server.2=...
* server.3=...
*/
public class QuorumHierarchical implements QuorumVerifier {
private static final Logger LOG = LoggerFactory.getLogger(QuorumHierarchical.class);
// key为serverId,value为该server的weight
private HashMap<Long, Long> serverWeight = new HashMap<Long, Long>();
// key为serverId,value为该server所属的groupId
private HashMap<Long, Long> serverGroup = new HashMap<Long, Long>();
// key为groupId,value为该group所包含的的所有server的权重之和
private HashMap<Long, Long> groupWeight = new HashMap<Long, Long>();
// 集群中包含的组的数量。
// 若每个server为一个group,那么该变量就变为了server的数量
private int numGroups = 0;
// 存放当前版本的动态配置中所有的server
private Map<Long, QuorumServer> allMembers = new HashMap<Long, QuorumServer>();
// 存放当前版本的动态配置中所有的participant
private Map<Long, QuorumServer> participatingMembers = new HashMap<Long, QuorumServer>();
// 存放当前版本的动态配置中所有的observer
private Map<Long, QuorumServer> observingMembers = new HashMap<Long, QuorumServer>();
// 当前动态配置的版本号
private long version = 0;
...
/**
* Verifies if a given set is a quorum.
* 验证给定的set是否是大多数
*/
public boolean containsQuorum(Set<Long> set) {
// 临时集合变量
// key为groupId,value为当前set中该groupId的所有server的weight之和
HashMap<Long, Long> expansion = new HashMap<Long, Long>();
/*
* Adds up weights per group
*/
LOG.debug("Set size: {}", set.size());
if (set.size() == 0) {
return false;
}
for (long sid : set) {
// 获取当前遍历的server所属的groupId
Long gid = serverGroup.get(sid);
if (gid == null) {
continue;
}
// 若当前expansion中没有该gid,那么当前遍历的这个server就是这个group的第一个server,
// 就将当前遍历server的weight作为该group的权重之和写入expansion
if (!expansion.containsKey(gid)) {
expansion.put(gid, serverWeight.get(sid));
} else {
// 若当前expansion中已经存在这个gid了,那么就将当前遍历server的weight追加到这个
// group的weight之和中
long totalWeight = serverWeight.get(sid) + expansion.get(gid);
expansion.put(gid, totalWeight);
}
}
/*
* Check if all groups have majority
*/
int majGroupCounter = 0;
for (Entry<Long, Long> entry : expansion.entrySet()) {
// 获取当前遍历的group
Long gid = entry.getKey();
LOG.debug("Group info: {}, {}, {}", entry.getValue(), gid, groupWeight.get(gid));
// entry.getValue() 是当前遍历group的totalWeight
// 判断当前遍历group的totalWeight是否大于当前组总权重之和的一半,
// 若大于,计数器加一
if (entry.getValue() > (groupWeight.get(gid) / 2)) {
majGroupCounter++;
}
}
LOG.debug("Majority group counter: {}, {}", majGroupCounter, numGroups);
// 若大多数group都满足前面的条件,则返回true,
// 表示当前版本的QuorumVerifier对ackset的判断是过半的
if ((majGroupCounter > (numGroups / 2))) {
LOG.debug("Positive set size: {}", set.size());
return true;
} else {
LOG.debug("Negative set size: {}", set.size());
return false;
}
}
...
}本篇主要分析集群选举通信原理及流程结构,以及重要类和成员变量。接下来,我们进行源码分析。