21. 源码| 树形数据结构
1. 前话
一提到ZK的数据结构,对ZK稍微有点了解的人,都会立马说ZK的内部实际上就是一个树形结构,每创建一个节点,就相当于在树形结构中添加一个节点。实际上,这样说确实没毛病,但有点过于表面了,没有回答全面,例如下面两个问题:
- 树形结构是如何构成的?更偏向于什么树?
- ZK对于这个树形结构有没有做其它的优化让树的查找更加快速?
本篇将会从上述的两个疑问出发,来进一步探究ZK的数据结构细节。
2. 树结构总览
ZK的树形结构类为DataTree,成员属性为dataTree的形式保存在数据库对象类ZKDatabase中,若要操作树形结构对象,则必须通过ZKDatabase类的方法才行。类的简要关系图如下:
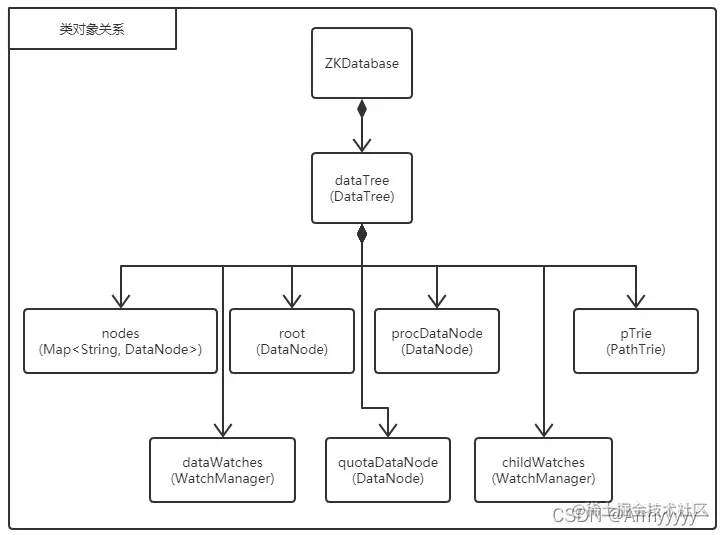
DataTree类中包含了图中七个重要的成员属性,稍微介绍下这七个主要成员属性作用:
Map<String, DataNode> nodes:实际类型是ConcurrentHashMap,这个集合将会保存树形结构的所有路径-节点对象映射关系,也就是说树形结构中存在多少个节点,集合中就会有多少个元素;DataNode root:树形结构的根节点,树进行序列化和反序列化时会操作该对象;DataNode procDataNode:在初始化时创建/zookeeper路径节点,如果后面有节点的前缀是/zookeeper将会挂在该节点下,ZK官方的作用定义为用作管理或表现状态的路径节点;DataNode quotaDataNode:实现节点配额的父节点,所有树节点的配额都会挂在该节点下,路径为/zookeeper/quota;WatchManager dataWatches:用于监听传入的当前节点事件,详细如何处理的等第三节监听再细说;WatchManager childWatches:用于监听该节点的子节点事件,详细如何同上;PathTrie pTrie:保存quota配额节点的路径树信息。
上面有两个成员属性的介绍是专门为quota配额信息来服务的,简单的介绍一下什么是配额信息:
ZK的数据结构是树形结构,且节点是没有相关的统计字段的,那这就导致一个问题,如果要统计某个节点下的 节点数量 及 数据大小,在不修改原有节点数据结构的情况下只能在别处增加相关信息。ZK的解决方式就是在树结构中增加/zookeeper/quota节点路径(节点对象为quotaDataNode),并且会将路径信息以单词字典树的形式存放在PathTrie中。
在配额路径中,zookeeper_limits存放的是节点数量和节点数据大小限制信息,zookeeper_stats存放的是当前路径的节点数量和节点数据统计信息
3. 树结构变化演示
3.1 树初始状态
ZK服务器启动后Map<String, DataNode> nodes对象的初始状态图如下:
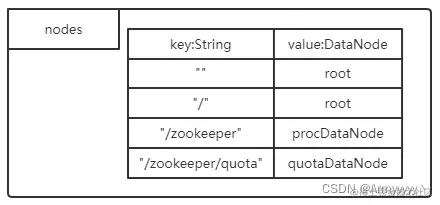
其中第一、二个元素,都是root根节点路径,另外两个节点路径则是ZK用于管理树信息的节点。
DataNode root对象的初始状态如下图:
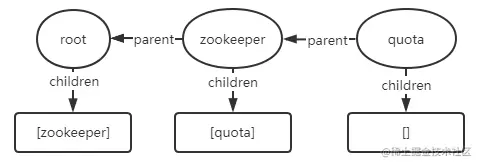
图中椭圆形的代表DataNode类型,下面的圆角长方形则是类型Set<String>的集合,且树结构中只有子节点->父节点的关系,没有父节点->子节点的关系。
那问题来了,要获取对应的子节点怎么办呢?很简单,前面的Map<String, DataNode> nodes对象包含了所有的路径和节点对应关系,ZK来获取节点信息一定是根据path路径来获取的,因此可以直接从nodes中获取到对应的节点,只要path是子节点的路径即可,时间复杂度O(1)。
那ZK为什么还要在DataNode中保留Set<String> children集合呢?个人猜测只是为了更容易判断节点下面是否已经存在该节点,当使用路径找到了父节点,用Set<String>集合的contains()方法简单判断一下即可知道该节点是否已经存在,时间复杂度即为O(1)。
所以ZK维护Map<String, DataNode> nodes全部节点和路径的映射关系,和DataNode中使用Set<String> children集合,都是以空间换时间,来实现ZK的高性能。
3.2 添加节点树的变化
假设在初始状态下,按照以下顺序依次添加、删除节点:
- create节点
/custom_parentA; - create节点
/custom_parentB; - create节点
/custom_parentC/child1; - create节点
/custom_parentA/child1; - create节点
/custom_parentB/child1; - create节点
/custom_parentB/child2; - delete节点
/custom_parentB/child2; - create节点
/custom_parentA/child1/c_child1;
以下是树结构发生的变化:
create节点/custom_parentA:
image.png create节点/custom_parentB:
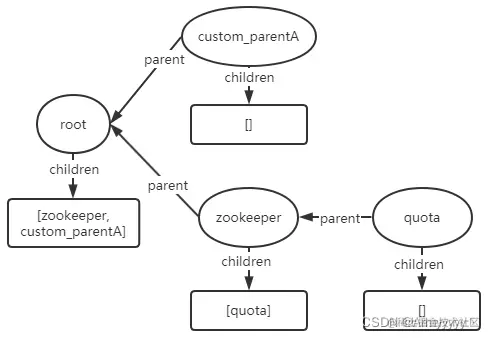
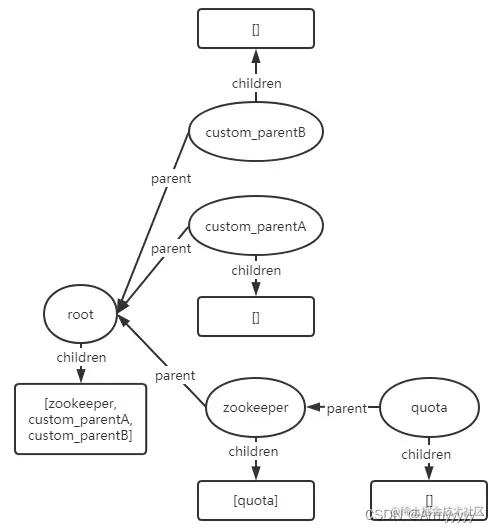
- create节点/custom_parentC/child1:由于child1的父节点custom_parentC并不存在,因此会报KeeperException.NoNodeException()异常;同理,假如父节点不存在,则会报KeeperException.NodeExistsException()异常。
- create节点/custom_parentA/child1:
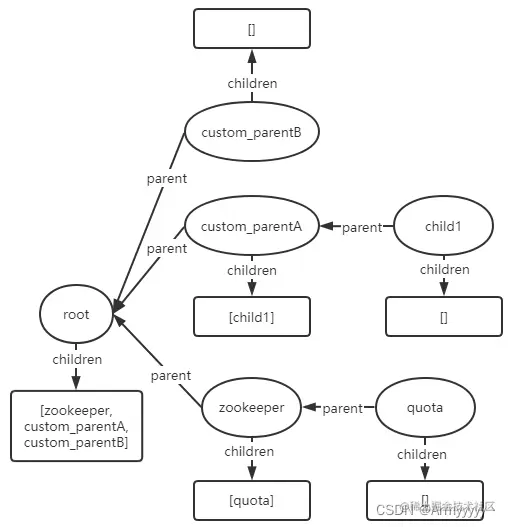
- create节点/custom_parentB/child1:
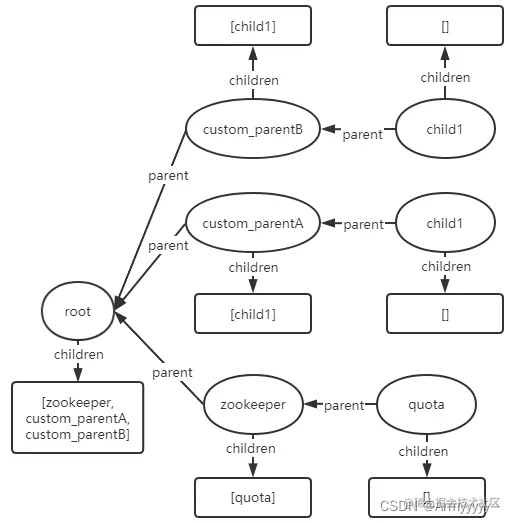
- create节点/custom_parentB/child2:
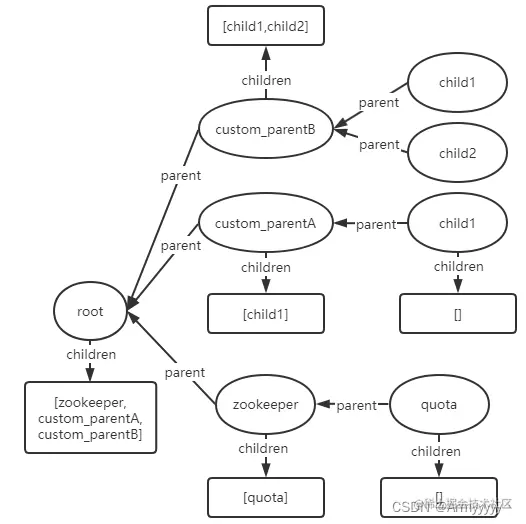
- delete节点/custom_parentB/child2:
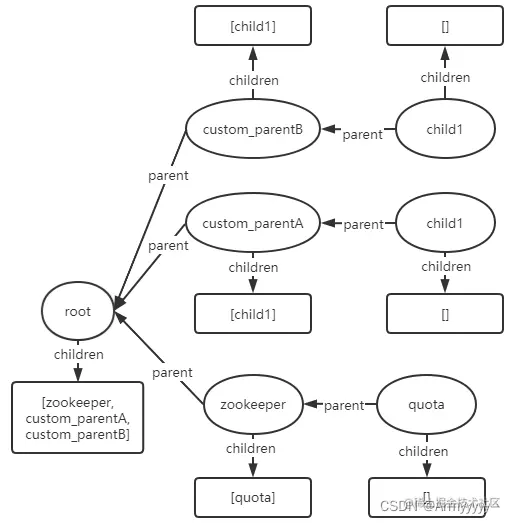
- create节点/custom_parentA/child1/c_child1:
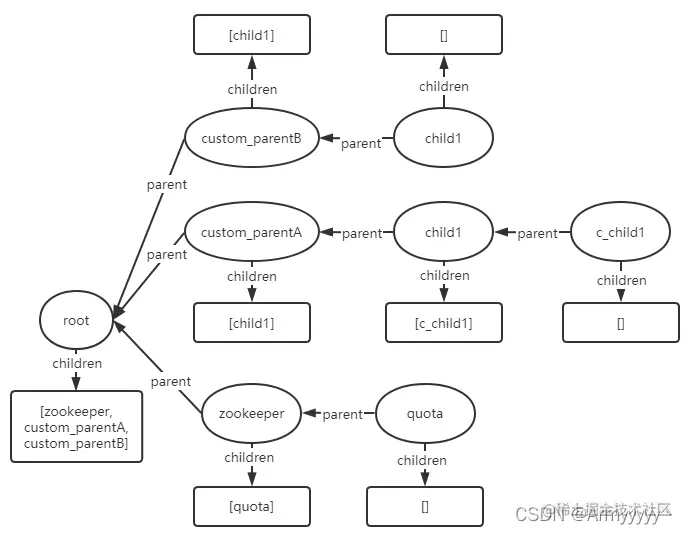
至于Map<String, DataNode> nodes集合中的值,则是以对应的path为key,DataNode对象为value存放在Map集合中的,就不用一一表明了。经过上面八个步骤演示,相信各位对ZK数据节点变化对应的数据结构改变流程应该有了十分直观的理解了。
本篇只是对ZK的数据结构做了一个简单的归纳,为后续解析Watcher的实现原理做个铺垫。